2.3_多GPU
2.3 多GPU
本节将探讨把多GPU安装在一个系统的不同方法及其对CUDA开发者的影响。为了讨论方便,我们会从下面的图中略去GPU内存。图中,每个GPU默认连接到相应专用内存。
大约在2004年,英伟达推出了“速力”(Scalable Link Interface,SLI)技术,可以让多GPU并行工作,以提供更高的图形性能。使用可以容纳多个GPU的主板,用户可以通过在他们的系统上安装两个GPU来提升近一倍的图形性能(图2-10)。默认情况下,英伟达驱动程序配置了这些GPU卡,使它们表现得好像是单个速度更快的卡,用以加速如Direct3D和OpenGL GPU的图形API。打算使用CUDA的最终用户,必须明确在Windows的显示控制面板上启用它。
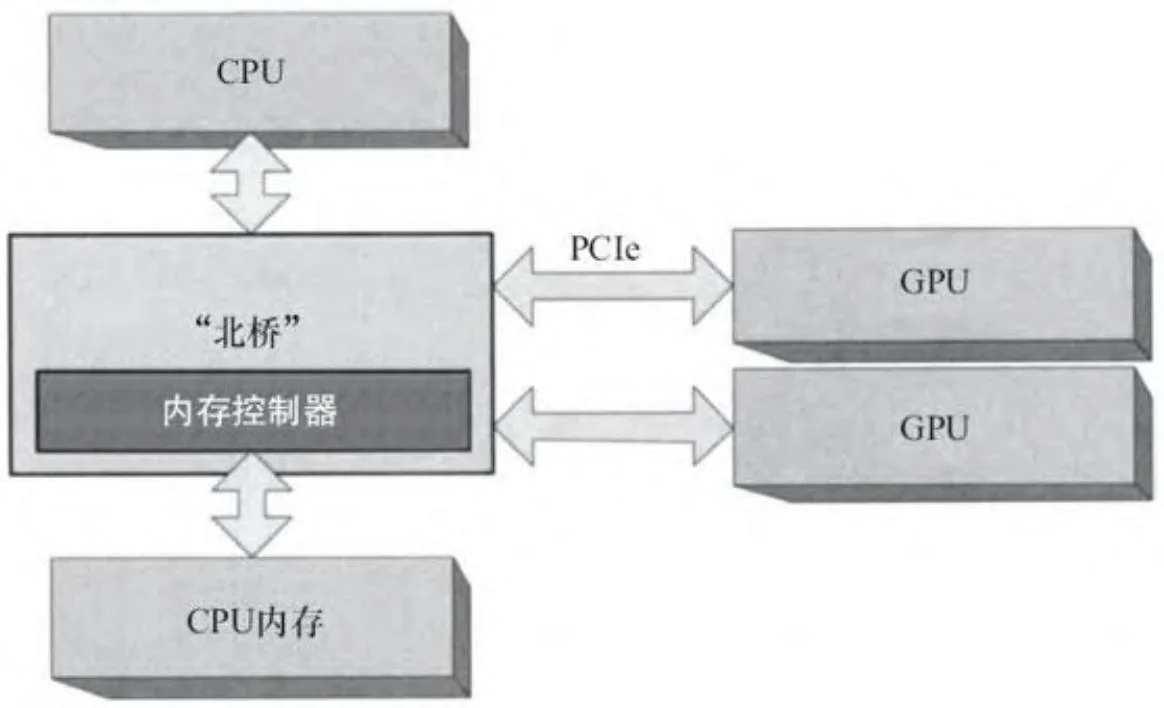
图2-10 多插槽GPU
还可以构造有多个GPU的GPU板(图2-11)。这种板的例子有 GeForce 9800GX2(双G92)、 GeForce GTX295(双GT200)、 GeForce GTX590(双GF110)和 GeForce GTX690(双GK104)。这类GPU板上的 GPU之间仅有桥接芯片是共享的,该芯片使一对GPU芯片可以通过PCIe交换信息。但它们并不共享内存资源,每个GPU都拥有一个集成内存控制器,使连接到GPU的内存具有全带宽性能。板上的GPU可以通过点对点的内存复制来交换信息,只需使用桥接芯片成功绕过主要的PCIe通道。此外,如果它们是费米架构或更高级别的GPU,那么每个GPU都可以映射属于其他GPU的内存到其全局地址空间里。
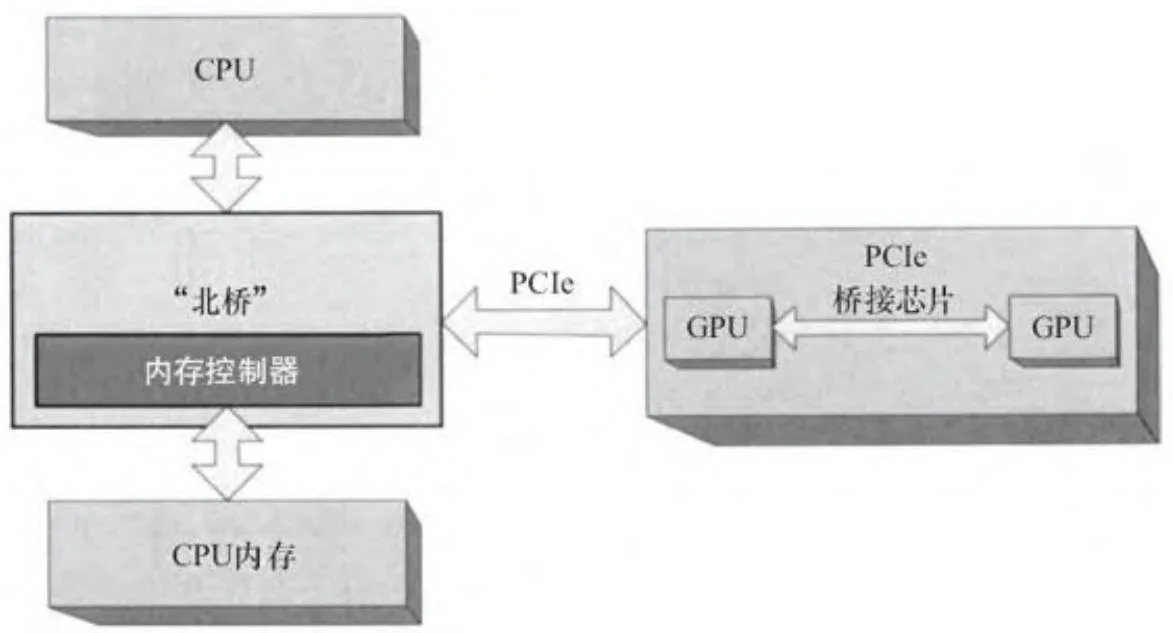
图2-11 多GPU板
SLI可以使用户能够像使用单个GPU一样使用多个GPU,只不过性能更快(通常多个GPU在同一块电路板上,如图2-11所示)。当图形应用程序下载纹理或者其他数据时,英伟达的显卡驱动程序会将数据和大部分渲染命令以广播的方式传送到每个GPU。而渲染命令可能会有一些小的变化,以使每个GPU控制的那部分输出缓冲区得以渲染。由于SLI导致多GPU表现为单个GPU,并且CUDA应用程序不能像图形应用程序那样透明地得到加速,所以CUDA开发人员一般不使用SLI。
这种双GPU板设计超支了供GPU使用的PCIe带宽。由于只一个PCIe插槽对应的带宽供板上的一对GPU使用,传输受限型工作任务的性能将遭受负面影响。如果有多个PCIe插槽可供选择,最终用户就可以安装多个双GPU板。如图2-12就显示了装载了4个GPU的机器。
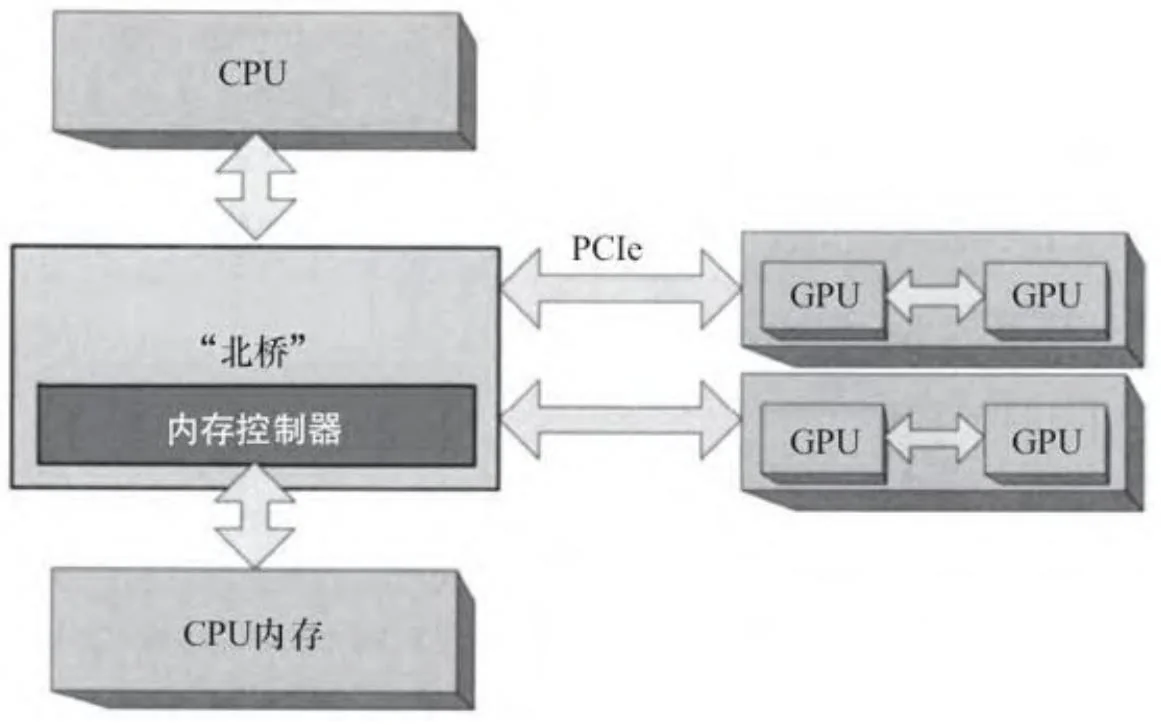
图2-12 多插槽式多GPU板
如果有多个如图2-6中系统的PCIe I/O集线器,NUMA系统考虑的布局和线程亲和将适用于插入该配置的单GPU板。
如果芯片组、主板、操作系统和驱动程序支持,甚至可以把更多的GPU装载进系统中。安特卫普大学(University of Antwerp)的研究人员,通过将4个GeForce 9800GX2整合到一个单一桌面电脑里,构建了一个叫做FASTRA的8-GPU系统,引起一时轰动。一个基于双PCIe芯片组构建的类似系统看起来如图2-13所示。
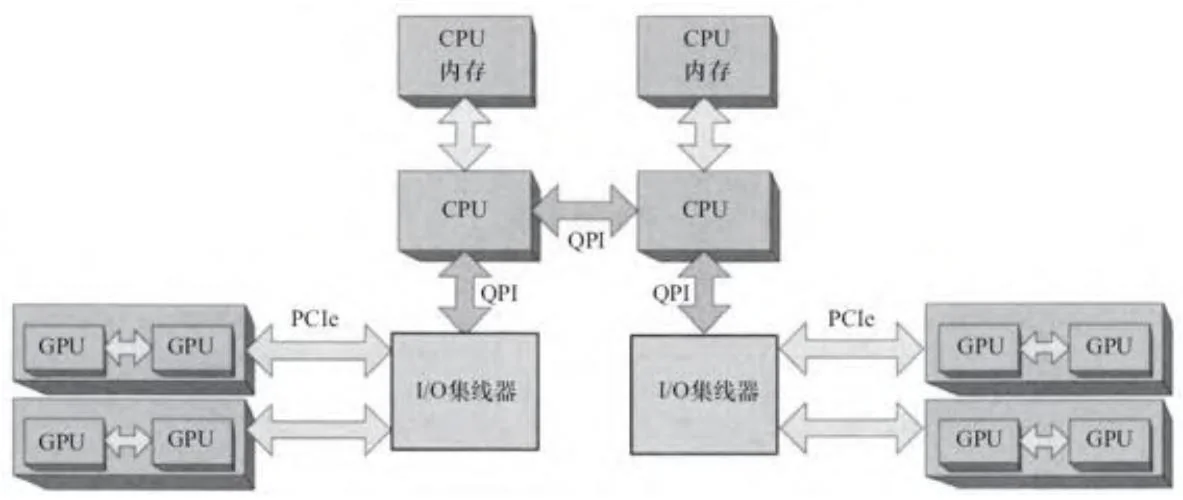
图2-13 多GPU板与多I/O集线器连接图
作为边注,点对点内存访问(其他GPU设备内存的映射,而不是内存复制)不能跨越I/O集线器工作,也不适用于集成了PCIe插槽的沙桥CPU。