2.4_CUDA中的地址空间
2.4 CUDA中的地址空间
每个CUDA初学者都知道,CPU和GPU的地址空间是分开的。CPU不能读取或写入GPU的设备内存,反过来,GPU也无法读取或写入CPU的内存。其结果是,应用程序必须明确地从GPU的内存中传入/传出数据,以对其进行相应处理。
实际情况比较复杂,CUDA已经增加了许多新的功能,如映射锁页内存和点对点访问。本节将以详细说明地址空间在CUDA中如何工作为第一要义。
2.4.1 虚拟寻址简史
虚拟地址空间是如此普遍和成功的抽象物,大多数程序员每天都使用它们,并从中受益,却不知道它们的存在。早期的人们发现,给计算机中的内存位置分配连续编号是非常有用的。虚拟地址空间是这一发现的延伸。其标准度量单位是字节,例如,64KB内存中的计算机的内存位置由0到65535。指定内存位置的16位值称为地址,地址的计算和相应内存位置上的操作过程则统称为寻址(addressing)。
早期的计算机进行物理寻址。它们会计算内存位置,然后读取或写入相应存储单元,如图2-14所示。随着软件越来越复杂,以及计算
机能承载多个用户或越来越普遍地运行多个作业,每个程序却可以读取或写入任何物理内存位置。很明显,这是不会被接受的!否则,机器上运行的软件很有可能会因为写入错误的内存位置而对其他软件造成致命破坏。除了健壮性问题,其还有安全方面的瑕疵:软件可通过读取属于其他人的内存位置来窥探其他软件。
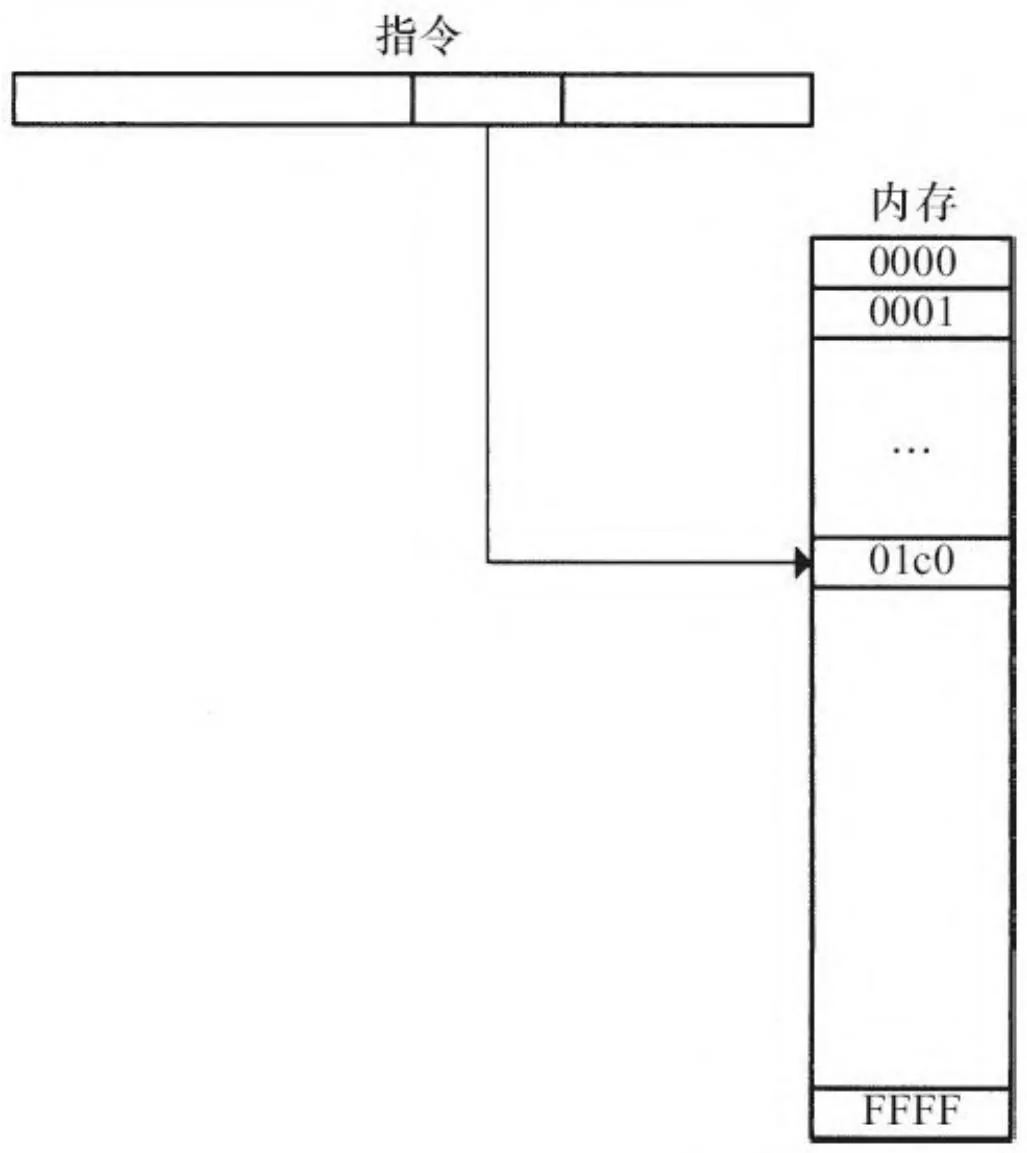
图2-14 16位地址空间简图
因此,现代的计算机推行虚拟地址空间。每个程序(操作系统设计者称其为一个进程)都会得到类似于图2-14中的内存视图,但每个进程都有自己的地址空间。未经操作系统特别许可,它们不能读取或写入属于其他进程的内存。机器指令使用虚拟地址而不是物理地址,随后由操作系统执行一系列查找表的操作,将其翻译成一个物理地址。
在大多数系统中,虚拟地址空间被划分成许多页,它们是寻址的单位,其大小至少4096字节。通常,硬件查找指定页内存的页表项(PTE)来得到所在物理地址,而不直接引用物理内存的地址。
我们可以很清楚地从图2-15看出,虚拟寻址能使一个连续的虚拟地址空间映射到物理内存并不连续的一些页。此外,当应用程序试图读取或写入页面未被映射到物理内存的内存位置时,硬件会发送必须由操作系统处理的错误信号。
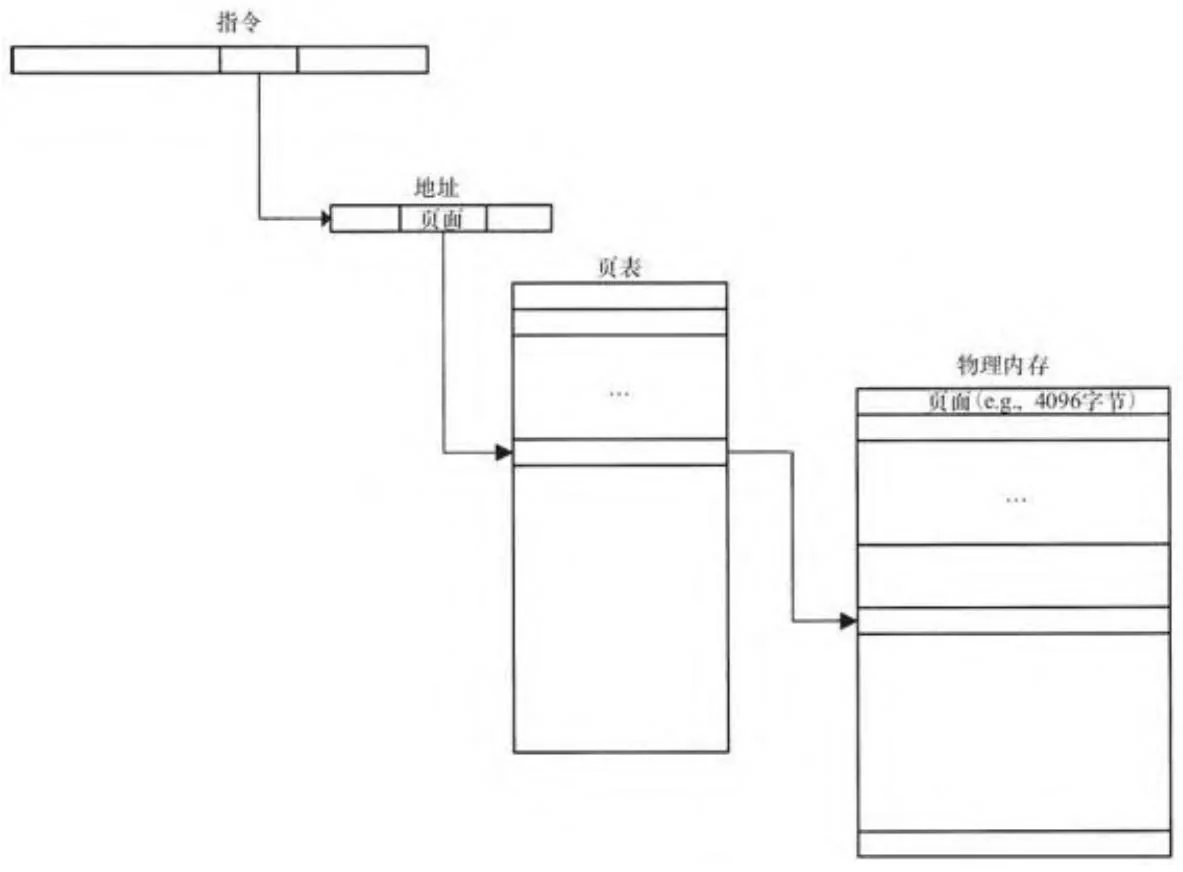
图2-15 虚拟地址空间
另外做个边注:实际上,所有硬件都不会实现如图2-15所示的单级页表。最起码,地址会被分成至少两个索引:第一个索引指向页表的“页目录”,第二个索引代表第一个索引约束下选择的页表。这种分层设计减少了页表所需的内存量,把不活跃的页表标记为非常驻状态并交换到磁盘上,就像无效页面一样。
除了物理内存位置,PTE还包含了在做地址转换时硬件可以验证的权限位。例如,操作系统可以使内存页只读。此时,如果应用程序试图写入该页面,硬件将会产生一个错误信号。
操作系统使用虚拟内存硬件来实现很多功能:
·缓式分配(lazy allocation):通过设置PTE允许分配无物理内存支持的页,从而可以分配大容量的内存。如果请求内存的应用程序碰巧访问这些页面,操作系统会立刻找到一个有物理内存的页面并解决这个故障。
·请求式调页(demand paging):内存可以被复制到磁盘中并且页面被标记为“非常驻”。如果这样的内存再次被引用,硬件会产生“页面故障”信号,而且操作系统会将数据复制到一个物理页中并修正PTE指向该页,然后继续执行。如此,故障得以解决。
·写时复制(copy-on-write):通过创建第二组映射到相同的物理页面的PTE,并将两组PTE标记为只读,虚拟内存得以“复制”。如果硬件捕获到一个试图写入这些页面的操作,操作系统将会复制该组页面到另一组物理页面,并再次标志这两组PTE为可写,然后恢复执行。如果应用程序只写入一个很小比例的“复制页面”,写时复制也就在性能上具有明显优势。
映射文件I/O(mapped file I/O):文件可以被映射到地址空间,并且通过访问文件可以解决页面故障。对进行随机访问相关文件的应用程序,通过委托操作系统中高度优化的VMM代码进行内存管理是非常有用的,特别是因为它是紧密耦合的大容量存储驱动程序。
CPU所执行的每一次内存访问都会有地址转换,明白这点是很重要的。为了使这个操作快捷,CPU包含了一些特殊的硬件:被称为转换旁置缓冲器(translation lookaside buffer,TLB)的缓存以及“页面查询器”(page walker)。前者的作用是保留最近转换的地址区间;后者的作用是通过读取页表来处理在TLB中未命中的缓存。[1] 现代的CPU还包括了支持“统一的地址空间”的硬件,可以让多CPU通过AMD的HT(超传输)和英特尔的快速通道互连(QPI),有效地访问另一个内存。由于这些硬件设施可以使CPU使用统一的地址空间来访问系统中的任何内存位置,所以本节前文在提到“CPU”和“CPU地址空间”时未提及系统中CPU的数量。
附注:内核模式和用户模式
关于CPU的内存管理的最后一点是操作系统的代码必须使用内存保护,以防止应用程序破坏操作系统自身的数据结构(例如,控制地址转换的页表)。为了协助内存保护,操作系统拥有一个执行任务的“特权”模式,可以在实现关键的系统功能时使用。为了管理页表等低层次硬件资源,抑或是对磁盘、网络控制器、CUDA GPU等外设上的硬件寄存器进行编程,CPU必须在内核模式下运行。应用程序代码所使用的非特权执行模式称为用户模式。[2]除了操作系统提供商编写的代码,控制硬件外设的低级别驱动代码也在内核模式下运行。由于内核模式代码的错误可能会导致系统稳定性或安全性问题,内核模式
代码会秉承一个更高的质量标准。此外,许多操作系统服务,如映射文件I/O或上面列出的设施外的其他内存管理,都不能在内核模式中使用。
为了保证系统的稳定性和安全性,用户模式和内核模式之间的接口是经过精心设计的。用户模式代码必须在内存中设立一个数据结构,并执行一个特殊的系统调用来验证内存和发出的请求的有效性。这种从用户模式到内核模式的过渡称为一个内核转换。内核转换代价不小,会增加CUDA开发者的成本。
每次用户模式驱动程序下实现的CUDA硬件交互都要由内核模式代码进行仲裁。这通常意味着它代其分配内存资源,以及硬件寄存器等硬件资源。例如,用户模式驱动程序下的硬件寄存器可以把任务提交给硬件。
大部分CUDA的驱动程序是在用户模式下运行。例如,为了分配系统锁页内存(例如,使用CUDAHostAlloc()函数),CUDA的应用程序会调用用户模式下的CUDA驱动程序,然后组成一个内核模式下的CUDA驱动程序请求,并执行内核转换。内核模式下的CUDA驱动程序,混合使用低级别的操作系统服务(例如,它可能调用系统服务来映射GPU硬件寄存器)和具有硬件特性的代码(例如,对GPU内存管理硬件进行编程)来满足上述请求。
2.4.2 不相交的地址空间
虽然GPU硬件不如CPU支持那么丰富的功能集,CUDA也使用虚拟地址空间。GPU确实执行内存保护,所以CUDA程序不可以随机地读取或破坏其他CUDA程序的内存,也不可以访问还没有被内核模式驱动程序映射的内存。但是,GPU并不支持请求式调页,所以被CUDA分配的每一字节虚拟内存都必须对应一个字节的物理内存。此外,请求式调页功能是操作系统为实现前述特性而使用的基础硬件机制。
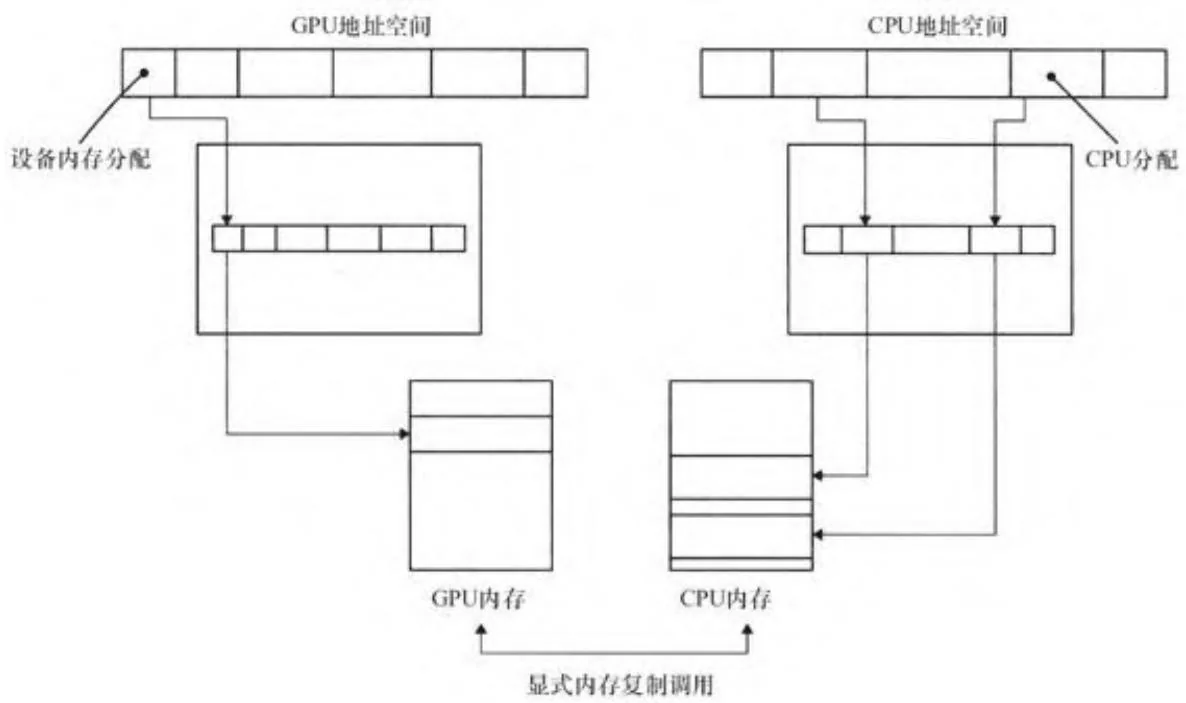
图2-16 不相交的地址空间
由于每个GPU有它自己的内存和地址转换硬件,GPU的地址空间和CUDA应用程序中的CPU地址空间是相互分开的。图2-16显示的是在使用映射锁页内存之前CUDA 1.0版的地址空间架构。CPU和GPU都有自己的
地址空间,用来映射各自设备自身的页表。两者的设备都要通过显式的内存复制命令来交换数据。GPU可以分配锁页内存,该内存是GPU为DMA映射的页面锁定的内存。它只能使DMA的速度更快,却不能让CUDA内核程序访问主机内存。[3]
CUDA驱动程序跟踪锁页内存的起止范围,并自动加速引用它们的内存复制操作。异步内存复制调用需要锁页内存起止信息,以确保在内存复制完成之前操作系统不会取消映射或移动物理内存。
并非所有的CUDA应用程序都可以分配到让CUDA使用的主机内存。例如,一个大型应用程序中的CUDA插件可能会在非CUDA代码分配的主机内存上操作。为了适应这种情况,CUDA 4.0增加了注册现有的主机内存地址起止范围(它可以锁定一个虚拟地址区间,并将其映射到GPU)以及跟踪数据结构的地址范围的能力,以便于让CUDA明白它是锁页内存。然后,内存就可以被传递给异步内存复制调用,否则,它将被看作是由CUDA分配的。
2.4.3 映射锁页内存
如图2-17所示,CUDA 2.2增加了一个叫做映射锁页内存的特性。映射锁页内存是被映射到CUDA地址空间的锁页主存,在CUDA内核程序里可以直接对其读取或写入。CPU和GPU的页表更新了,以便CPU和GPU中拥有指向相同主机内存缓冲区的地址区间。由于地址空间不同,GPU
指向该缓冲区的指针必须使用cuMemHostGetDevicePointre()或cudaHostGetDevicePointer()函数来查询。[4]
2.4.4 可分享锁页内存
如图2-18所示,CUDA 2.2还增加了一个叫做可分享锁页内存的特性。设置锁页内存“可分享”,会导致CUDA驱动程序把该内存映射给系统中的所有GPU,而不仅仅是当前上下文的GPU。此特性为系统中的CPU和所有GPU创建一组独立的页表条目,使相应的设备将虚拟地址转换成实际物理内存。主机内存的起止范围也被添加到了每个活跃的CUDA上下文的跟踪机制中,因此每个GPU都能识别出作为可分享方式分配的锁页内存。
图2-18可能表示了开发者对多地址空间的容忍限度。在这里的每个分配,双GPU系统有3个地址,而4GPU系统则有5个地址。虽然CUDA通过API能够快速查找一个给定CPU的地址空间范围,并传回相应的GPU地址空间范围,但在N个GPU的系统中将拥有N+1个地址且全部指向同一物理分配,这样是不方便的。
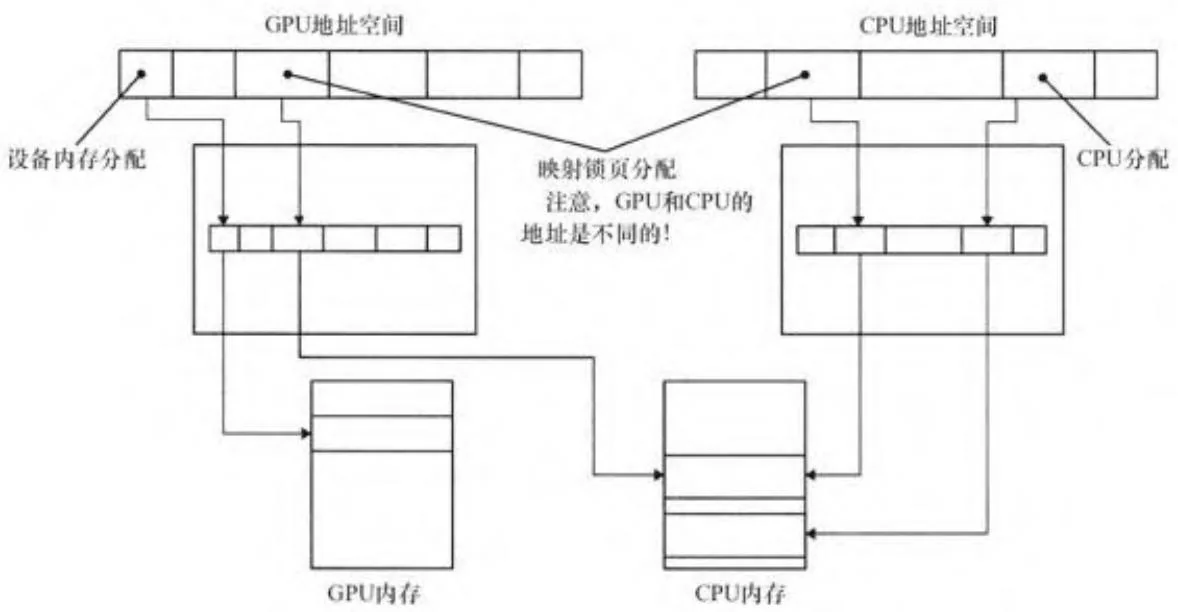
图2-17 映射锁页内存
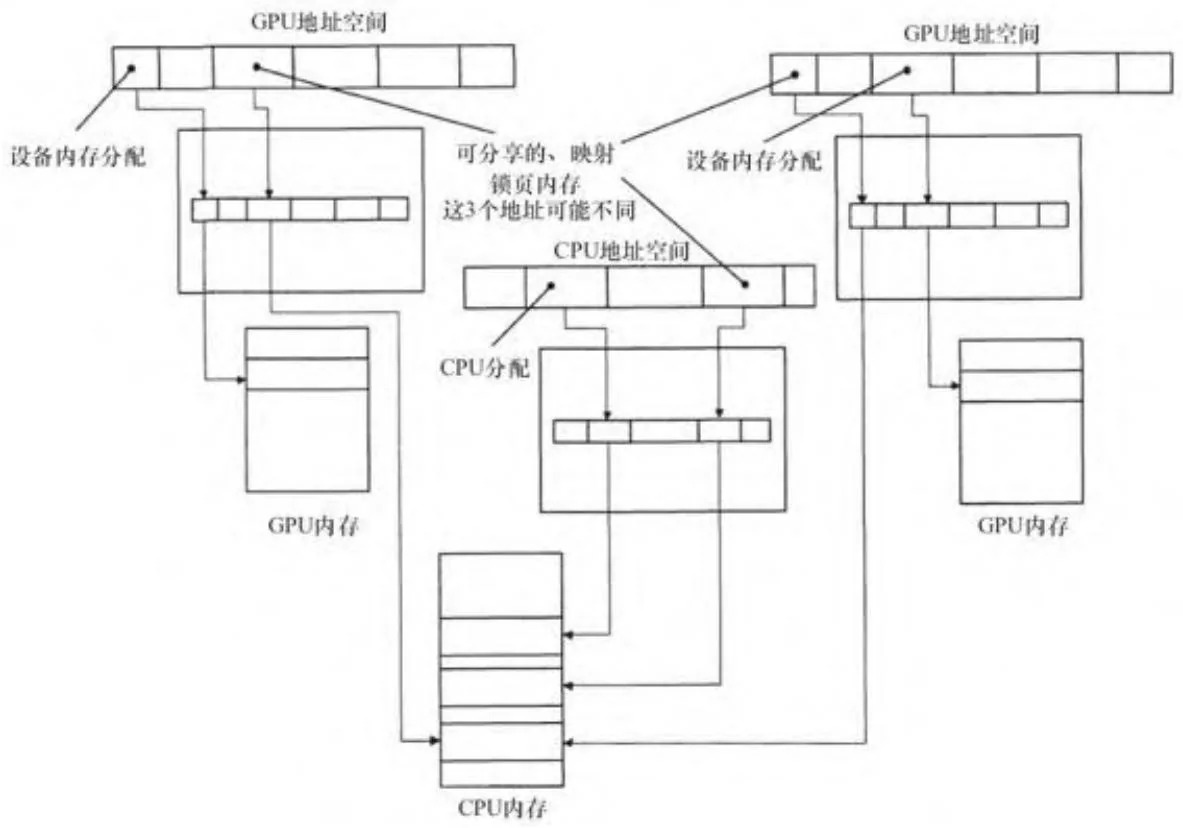
图2-18 可分享、映射锁页内存
2.4.5 统一寻址
32位CUDA GPU需要多个地址空间,它最多只能映射 的地址空间。由于一些高端的GPU有多达4GB的设备内存,所以它们很难在寻找所有设备内存地址的同时映射锁页内存,更不用说像CPU那样使用统一的地址空间了。但是,对于在费米架构或更高级GPU下的64位操作系统而言,如下的一个更简单抽象是可行的。
如图2-19所示,CUDA 4.0增加了一个叫做统一虚拟寻址(unified virtual addressing,UVA)的特性。当UVA生效时,CUDA会从相同的虚拟地址空间为CPU和GPU分配内存。CUDA驱动程序通过以下两步来完成上述任务:第一,初始化程序执行基于CPU地址空间的大型虚拟分配,该分配过程中可能会碰到无物理内存支持的情况;第二,将GPU分配的内存映射到上述地址空间。由于64位CPU支持48位虚拟地址空间[5],而CUDA GPU只支持40位,应用程序使用UVA时应确保CUDA被提前初始化,以保证CUDA所需要的虚拟地址先于CPU代码中的分配请求而被满足。
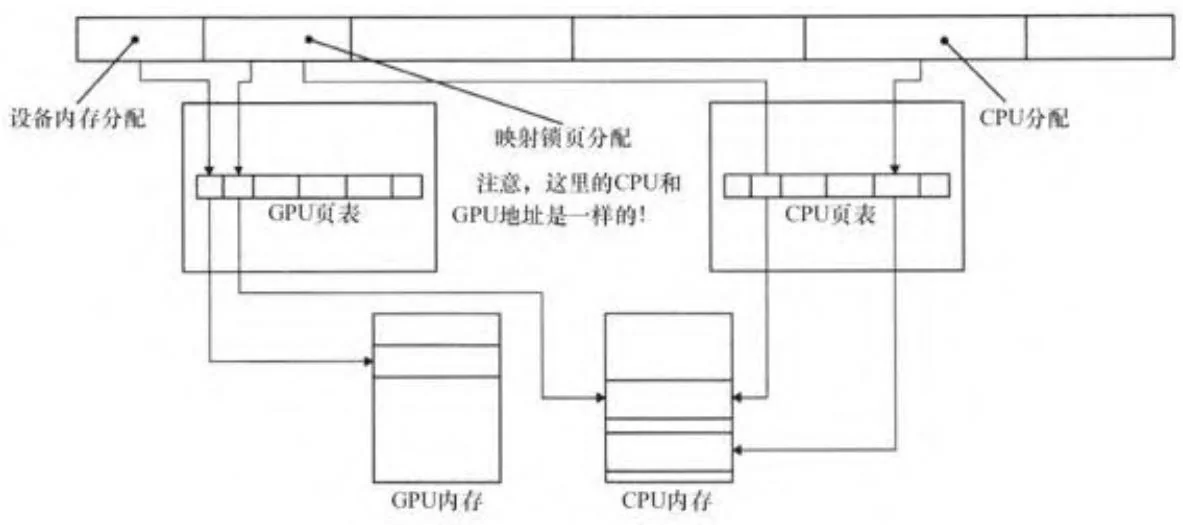
图2-19 统一虚拟寻址 (UVA)
对于映射锁页分配,GPU和CPU的指针是相同的。对于其他类型的分配,CUDA可以通过地址推断出既定分配存在于哪个设备。其结果是,线性内存复制函数族(需要指定方向的CUDAMemcpy()和cuMemcpyHtoD()、cuMemcpyDtoH()等)被更简单的cuMemcpy()和CUDAMemcpy()函数所替代,而后两个函数并不需要指定内存方向。
支持UVA的系统会自动启用UVA。在本书撰写过程中,使用TCC驱动程序的64位Linux、64位MacOS和64位Windows都支持UVA。然而,WDDM驱动程序暂时还不支持UVA。当UVA生效时,CUDA所执行的所有锁页分配都是被映射的和可分享的。对已被使用cuMemRegisterHost()函数分配为锁页的系统内存,需要注意设备指针仍然需要使用cu(da)HostGetDevicePointer()函数查询。即使在UVA生效时,CPU也不能访问设备内存。另外,默认情况下,GPU不能互相访问彼此的内存。
2.4.6 点对点映射
在介绍CUDA的虚拟内存抽象机制旅程的最后阶段,我们讨论一下点对点的设备内存映射如图2-20所示。点对点可以使费米架构GPU读写另一个费米架构GPU的内存。点对点映射仅支持启用UVA的平台,并且只对连接到相同I/O集线器上的GPU有效。由于使用点对点映射时UVA始终是有效的,不同设备的地址空间范围不重叠,并且驱动程序(和运行时)可以从指针值推断出所驻留的设备。
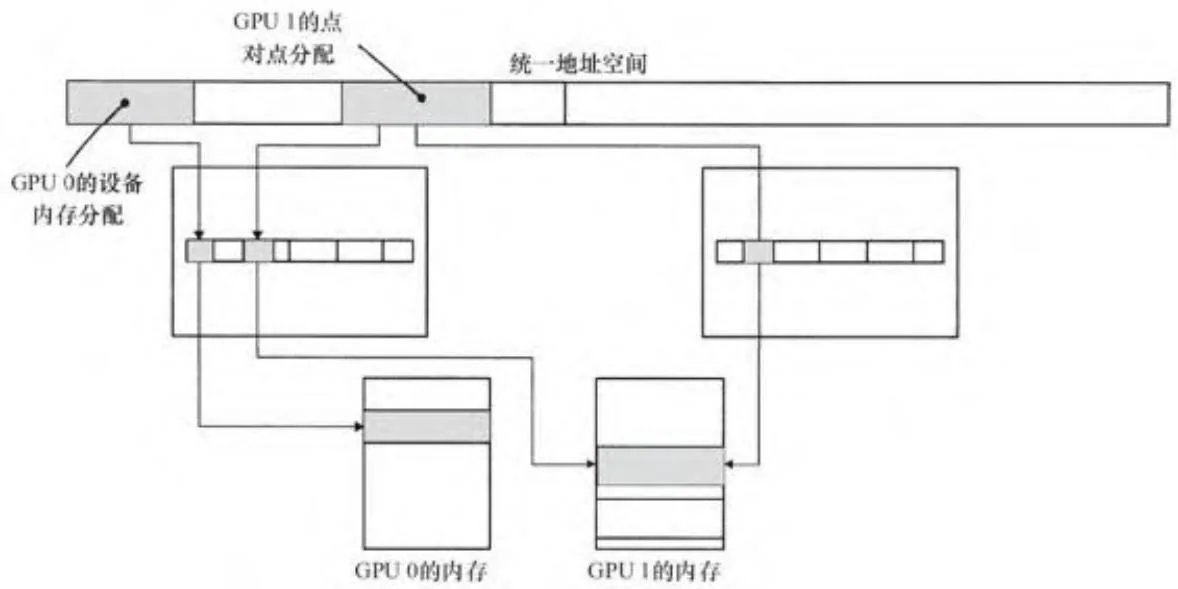
图2-20 点对点映射
点对点内存寻址是非对称的。例如,图2-20为非对称的映射,在该图中,对于1号GPU的内存分配,0号GPU是可见的,反之则不行。为了让GPU之间能够看到对方的内存,每个GPU必须显式地映射其他GPU的
内存。而对于用来管理点对点映射的API的函数,我们将在9.2节进行相应讨论。
[1] 编写程序(对于CPU和CUDA)来显示TLB的规模和结构以及页面查询器的内存开销,这也是有可能的(如果页面查询器在足够短的时间内通过足够的内存)。
[2] 内核模式和用户模式分别对应 x86 下的 “Ring 0” 和 “Ring 3” 术语。
[3] 在32位操作系统上,为了执行内存复制,支持CUDA的GPU可以映射锁页内存到一个40位地址空间里,而该空间已经超过了CUDA内核程序的控制范围。
[4] 对于多GPU配置,CUDA 2.2还增加了一个叫做“可分享锁页内存”的特性,导致上述分配会被映射到每个GPU的地址空间。但这并不能保证cu(da)HostGetDevicePointer()函数在不同GPU上会返回相同的值。
[5] 48位虚拟地址空间 。未来的64位CPU将支持更大的地址空间。