2.5_CPU与GPU交互
2.5 CPU/GPU交互
本节描述CPU/GPU交互的关键知识点如下。
·锁页主机内存:GPU可以直接访问的CPU内存;
·命令缓冲区:由CUDA驱动程序写入命令,GPU从此缓冲区读取命令并控制其执行;
CPU/GPU同步:指的是CPU如何跟踪GPU的进度。
本节在硬件层次上介绍这些设施,仅为帮助读者了解它们如何适用到CUDA开发的需要时才使用API。为了简单起见,本节使用图2-1中的CPU/GPU模型,省略了多CPU或者多GPU编程的复杂性。
2.5.1 锁页主机内存和命令缓冲区
出于某些显而易见的原因,CPU和GPU最擅长访问它们自己的内存,但是GPU可以通过直接内存访问(direct memory access,DMA)方式来访问CPU中的锁页内存。锁页是操作系统常用的操作,可以使硬件外设直接访问CPU内存,从而避免过多的复制操作。“被锁定”的页面已被操作系统标记为不可被操作系统换出的,所以设备驱动程序给
这些外设编程时,可以使用页面的物理地址直接访问内存。而CPU仍然可以访问上述锁页内存,但是此内存是不能移动或换页到磁盘上的。
由于GPU是不同于CPU的设备,DMA还可以使GPU读取和写入CPU内存的操作与CPU的执行操作相互独立且并行执行。我们必须注意CPU和GPU之间的同步,以避免竞争。而对于可以在GPU活动时有效利用CPU时钟周期的应用程序而言,并发执行具有显著的性能优势。
图2-21描绘了一个为直接访问而被GPU映射的“锁页”缓冲区[1]。CUDA程序员都很熟悉锁页缓冲区,因为CUDA一直允许他们通过CUDAMallocHost()等API来分配锁页内存。在表面下的内在机制中,对应这种缓冲区的主要应用程序之一是将命令提交到GPU。CPU将命令写入一个供GPU消耗的“命令缓冲区”,与此同时,GPU读取并执行先前写入的命令。图2-22显示的是CPU和GPU如何共享这个缓冲区。此图是被简化了的,因为这类命令可能是几百字节大小,而该缓冲区大到足够容纳几千个这样的命令。缓冲区的“前缘”正由CPU构建且尚未准备好供GPU读取,“后缘”正在被GPU读取。介于中间的命令全部准备就绪,只要GPU进程准备好了就可以进行传输。
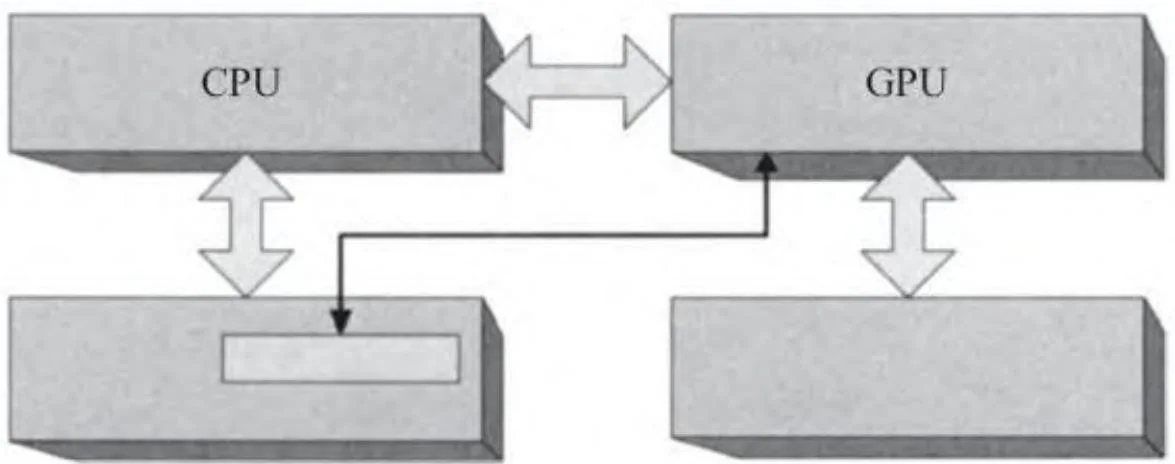
图2-21 锁页缓冲区
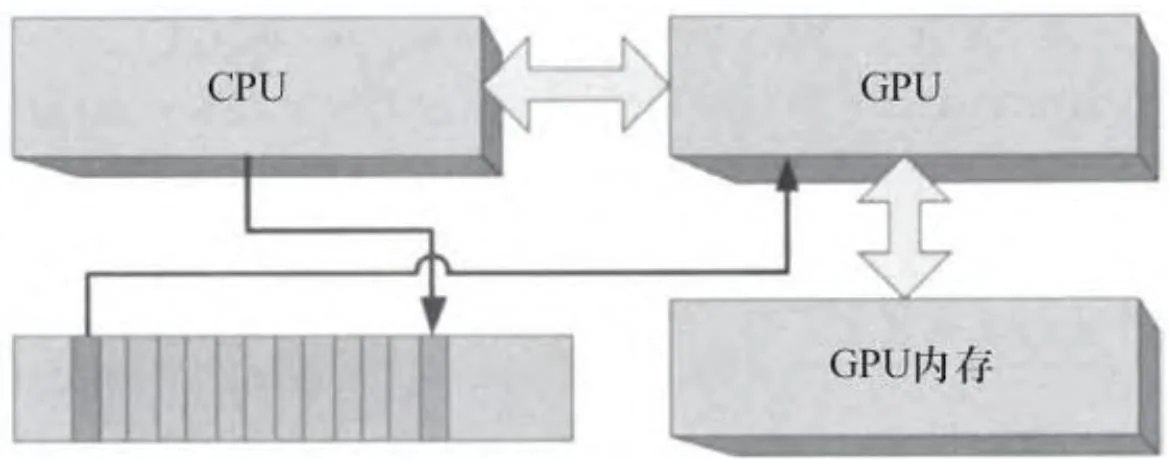
图2-22 CPU/GPU命令缓冲区
通常情况下,CUDA驱动程序可以重用命令缓冲区的内存,因为一旦GPU处理完一条命令后,该命令占用的内存可以被CPU重新写入。图2-23显示了CPU是如何“循环处理”命令缓冲区的。
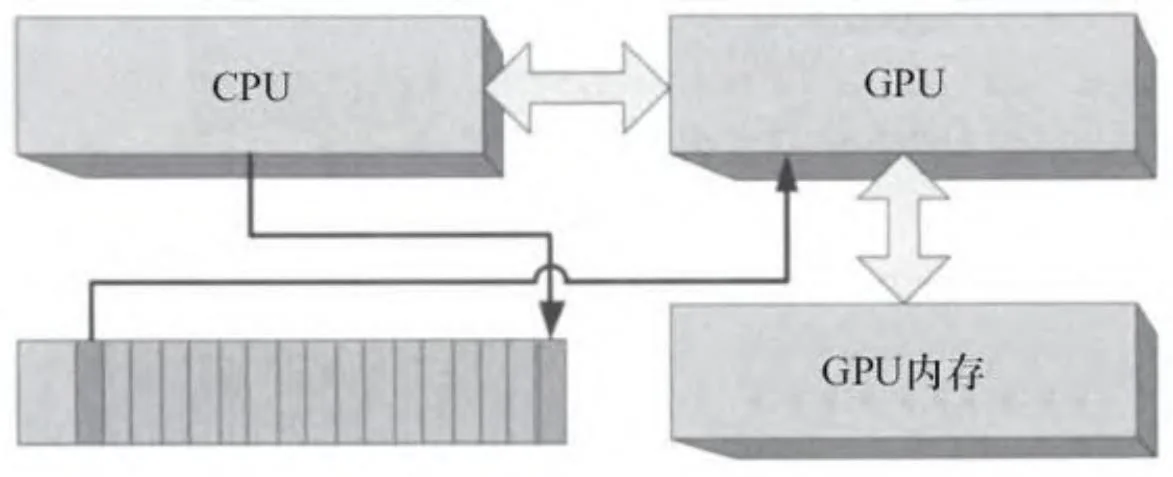
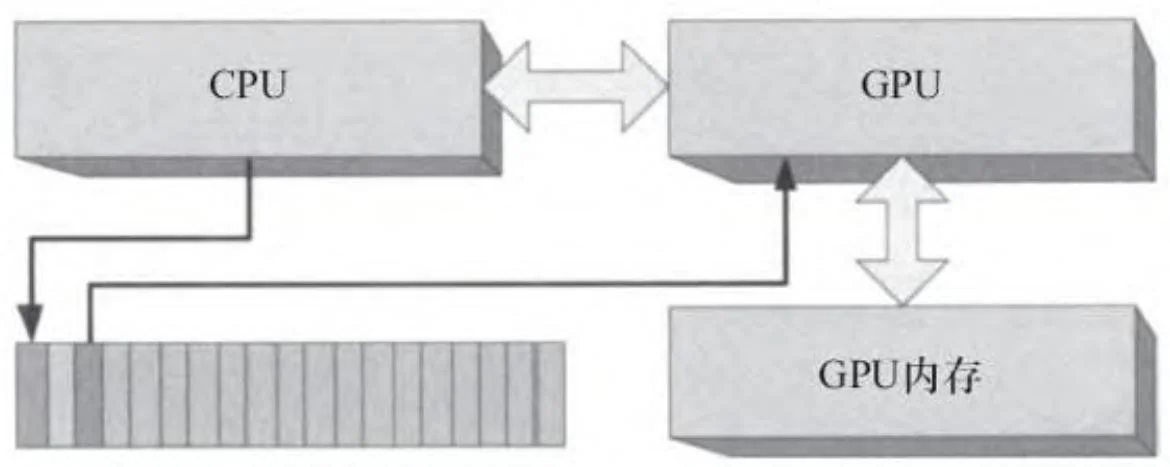
图2-23 命令缓冲区的循环处理
考虑到启动一个CUDA内核程序需要几千个CPU时钟周期,此时,一个CPU/GPU并发的重要方法是在GPU进行处理时准备更多的GPU命令。应用程序并不能均衡地保持CPU和GPU忙碌,有可能会出现“CPU受限”或“GPU受限”的情况,分别如图2-24和图2-25所示。在一个CPU受限型应用程序里,GPU随时就绪,只要下一个命令准备好就马上进行处理;而在一个GPU受限型应用程序里,CPU的命令缓冲区已经完全被填满,在写入下一GPU命令之前必须等待GPU处理完上一命令。有些应用程序
本质上是CPU或GPU受限型的,所以CPU和GPU受限并不一定说明应用程序的结构有什么本质的问题。然而,知道应用程序是CPU受限型的还是GPU受限型的有助于找出性能优化机会。
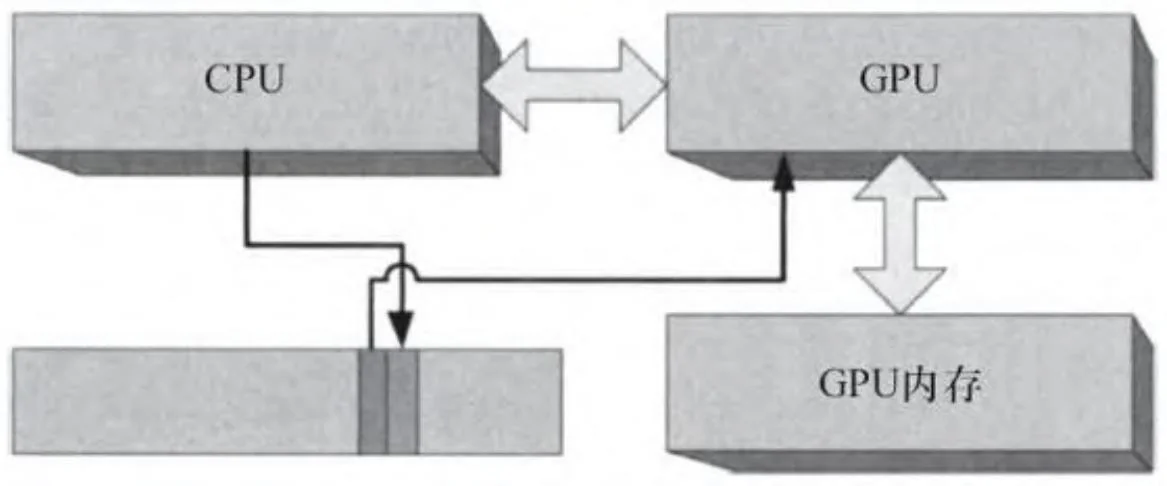
图2-24 GPU受限型应用程序
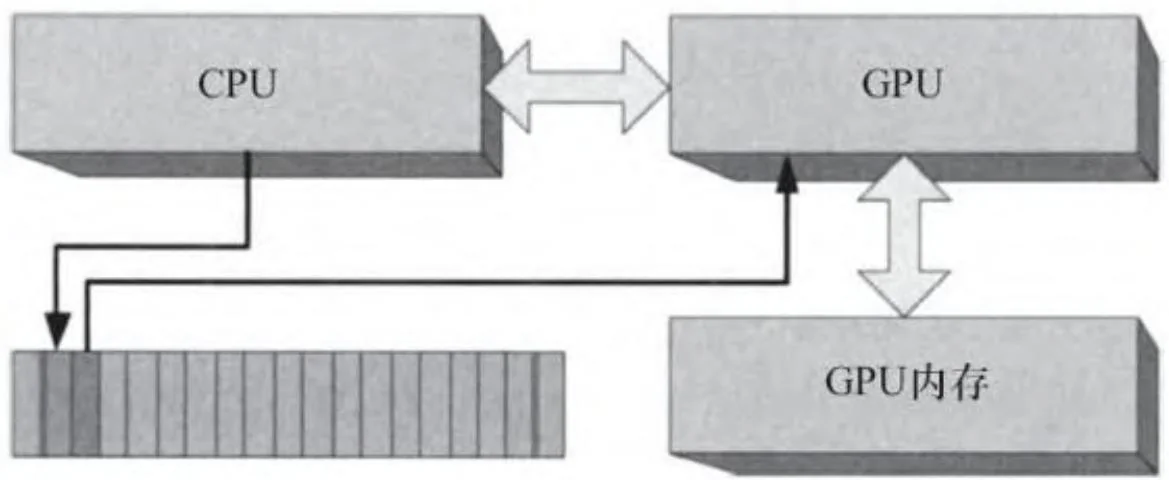
图2-25 CPU受限型应用程序
2.5.2 CPU/GPU并发
前一节介绍在CUDA系统可用的最粗粒度并行:CPU/GPU并发。CUDA内核程序的所有启动都是异步的:CPU通过将命令写入命令缓冲区来请求启动内核,然后直接返回,而不检查GPU进度。内存复制也可以选择异步方式,这使CPU/GPU并发以及可能使内存复制与内核处理并发执行。
1. 阿姆达尔法则(Amdahl’s Law)
当CUDA程序编写正确时,CPU和GPU可以完全地进行并行操作,这有可能使性能翻倍。然而CPU或GPU受限型程序不会从CPU/GPU并发得到太大好处,因为即使其他装置也是并行运行的,CPU或GPU的某一方也会限制整体性能。这种含糊不清的观察可以使用阿姆达尔法则正确描述,该定律于1967年在一篇论文中被吉恩·阿姆达尔(Gene Amdahl)首次阐明。[2] 阿姆达尔法则通常如下表示:
其中, 且 代表的是串行部分比率。在研究CPU/GPU并发等小规模的性能场合时,这一公式形式似乎不太方便。所以,将其变形成如下公式:
这清楚地表明,如果 ,则加速为 N 倍。如果 CPU 和 GPU 各有一个(N=2),那来自全并发的最大加速为 2 倍。对平衡工作负载这基本是可实现的,例如视频转码中,CPU 可以与 GPU 同时执行,其中 GPU 执行并行操作(如像素处理),而 CPU 执行串行操作(如可变长解码)。但对于更多的 CPU 或 GPU 受限型应用程序,这种类型的并发只能提供有限的优势。
对那些认为并行是解决一切性能问题的万能药的人来说,阿姆达尔的论文无异于一个警钟。我们将其应用于这本书中讨论内部GPU并发、多GPU并发,以及移植CUDA内核所得加速比等其他地方。它可以用来让我们知道哪些并发形式不能赋予一个给定的应用程序任何优势,因此开发人员可以把时间花在探索其他提高性能的途径上。
2. 错误处理
CPU/GPU并发也会对错误处理造成影响。当CPU开始启动一批内核而其中一个导致内存故障时,CPU并不能发现这一故障,直到它执行了CPU/GPU同步才行(在下一节描述)。开发人员可以手动执行CPU/GPU同步作为辅助,具体通过调用CUDAThreadSynchronize()、cuCtxSynchronize()等函数来完成。在诸如CUDAFree()或cuMemFree()的函数调用中也会导致CPU/GPU的同步。《CUDA C语言编程指南》中通
过使用可能会导致CPU/GPU同步的函数,提及了这一行为:“注意,这个函数也可能会从之前的异步启动返回错误代码。”
由于目前CUDA是并发执行的,如果真的发生了故障,我们并没有办法知道是哪个内核程序造成的故障。至于调试代码,如果难以通过同步操作来隔离故障,开发人员可以设置CUDA-LaUNCH_BLOCKING的环境变量,以迫使所有启动的内核同步。
3. CPU/GPU同步
CUDA的大多数GPU命令涉及内存复制或内核程序启动的执行,而也有一个重要的命令子集帮助CUDA驱动程序跟踪GPU处理命令缓冲区时的进展。由于应用程序不知道一个给定的CUDA内核程序会运行多久,所以GPU本身必须给CPU汇报工作进度。图2-26显示的是命令缓冲区和“同步位置”(也位于锁页主机内存上),它们被CUDA驱动程序和GPU使用,以跟踪相应进程。一个单调递增的整数值(“进度值”)是由驱动程序维护,每一个主要的GPU操作后都跟着一个将新进度值写入共享同步位置的命令。如图2-26中的例子,进度值将一直为3,直到GPU完成当前命令的执行并将4写入同步位置中为止。
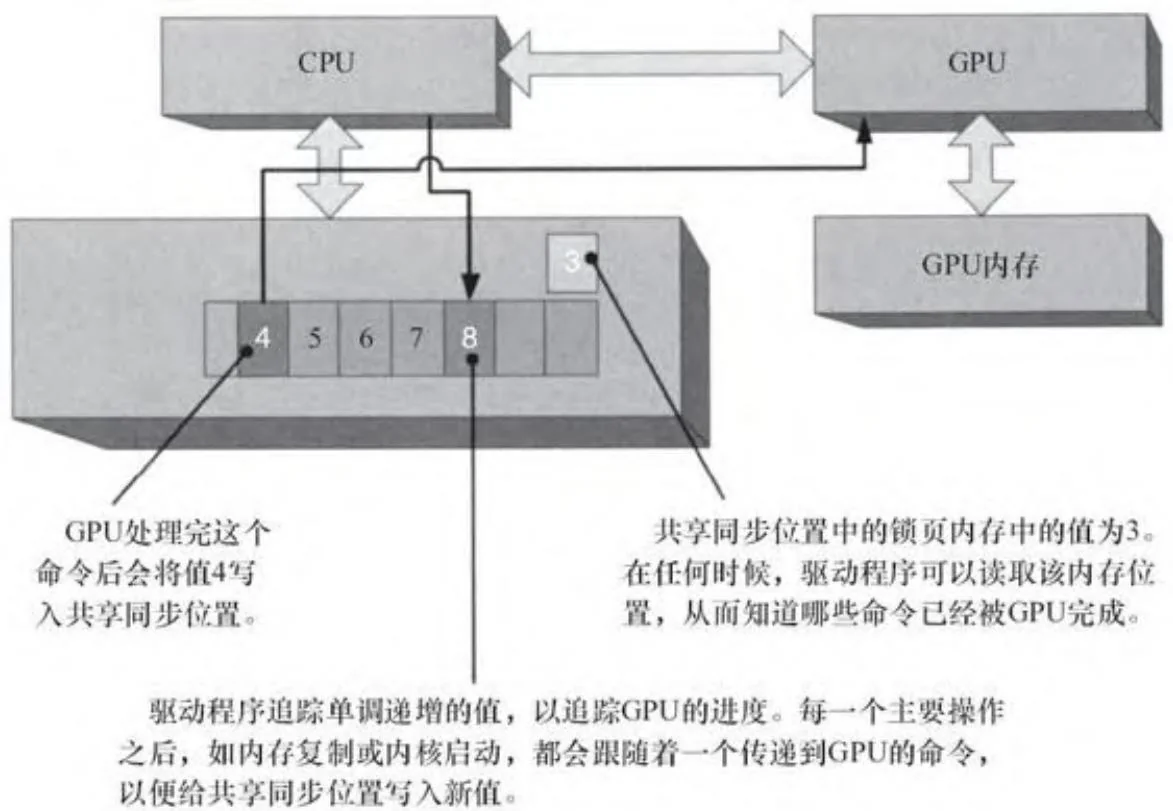
图2-26 共享同步值(条件满足前)
CUDA既隐式又显式地暴露了这些硬件功能。上下文范围的同步通过简单调用cuCtxSynchronize()、CUDAThreadSynchronize()等函数来检查GPU请求的最近同步值,并且一直等待,直到同步位置获得该值。例如,在图2-27中,如果由CPU写入的命令8之后紧接着cuCtxSynchronize()或CUDAThreadSynchronize()函数,则驱动程序将一直等待,直到共享同步值大于或等于8为止。
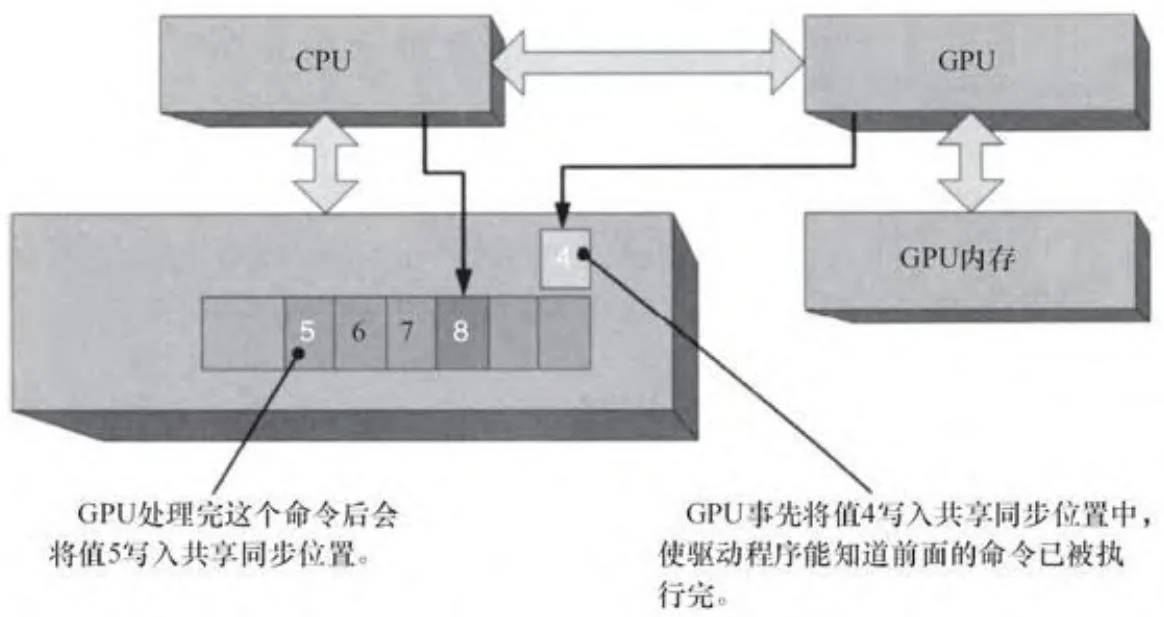
图2-27 共享同步值(条件满足后)
CUDA事件则更明确地暴露了这些硬件能力。cuEventRecord()函数的作用是将一个命令加入队列使得一个新的同步值写入共享同步位置中,cuEventQuery()和cuEventSynchronize()则分别用于检查和等待这个事件的同步值。
早期版本的CUDA只是简单地轮询共享的同步位置,反复地读内存,直到等待准则满足为止。但是这种方法代价很大,且只有当应用程序不必等待太久时才有用(即同步位置不一定要被读取很多遍,就可以因等待标准已经得到满足而退出)。对大多数应用程序来说,基于中断的方案(CUDA公开称为“阻塞同步”)更好,因为它们使CPU等待线程挂起,直到GPU发出中断信号为止。驱动程序将GPU中断映射到
一个特定的线程同步原语平台,如Win32事件或Linux的信号。当应用程序开始等待时,若等待条件不成立,这样做可以挂起CPU的线程。
通过指定CUCTX_BLOCKING_SYNC到cuCtxCreate()或指定CUDADeviceBlockingSync到CUDASetDeviceFlags(), 应用程序可以强制使用上下文范围的同步进入阻塞状态。然而, 使用阻塞的CUDA事件 (指定CU_EVENT_BLOCKING_SYNC到cuEventCreate()或指定CUDAEventBlockingSync到cuEventCreate()) 更可取, 因为它们粒度更细且可以与任何类型的CUDA上下文进行无缝互操作。
敏锐的读者可能会关注CPU和GPU在不使用原子操作或其他同步原语的情况下读取和写入这种共享的内存位置。但由于CPU只读取共享位置,竞争条件并不是关注点。这样,最坏的情况是CPU读取了一个“过时的”值,从而导致其等待时间要比实际的长。
4. 事件和时间戳
主机接口有一个机载高分辨率计时器,它可以在写入一个32位的同步值时同时写一个时间戳。CUDA使用这个硬件设施实现CUDA事件中的异步计时功能。
2.5.3 主机接口和内部GPU同步
GPU可能包含多个引擎,以使内核执行和内存复制并发进行。在这种情况下,GPU的驱动程序将写入一些命令,这些命令被分发到同时运行的不同引擎中。每个引擎都有自己的命令缓冲区和共享同步值,引擎进度的跟踪如图2-26和图2-27所述。图2-28显示的是两个复制引擎和一个计算引擎并行工作时的情形。其中,主机接口负责读取命令并将其调度到相应引擎。在图2-28中,一个主机到设备的内存复制操作和两个相关操作(一个内核启动和一个设备到主机的内存复制)已被提交给硬件。依据CUDA编程抽象模型,这些操作都是在同一个流上进行的。这个流就像是一个CPU线程,在内存复制之后接受内核启动的提交。因此,CUDA驱动程序为了实现内部GPU同步必须将命令插入主机接口的命令流中。
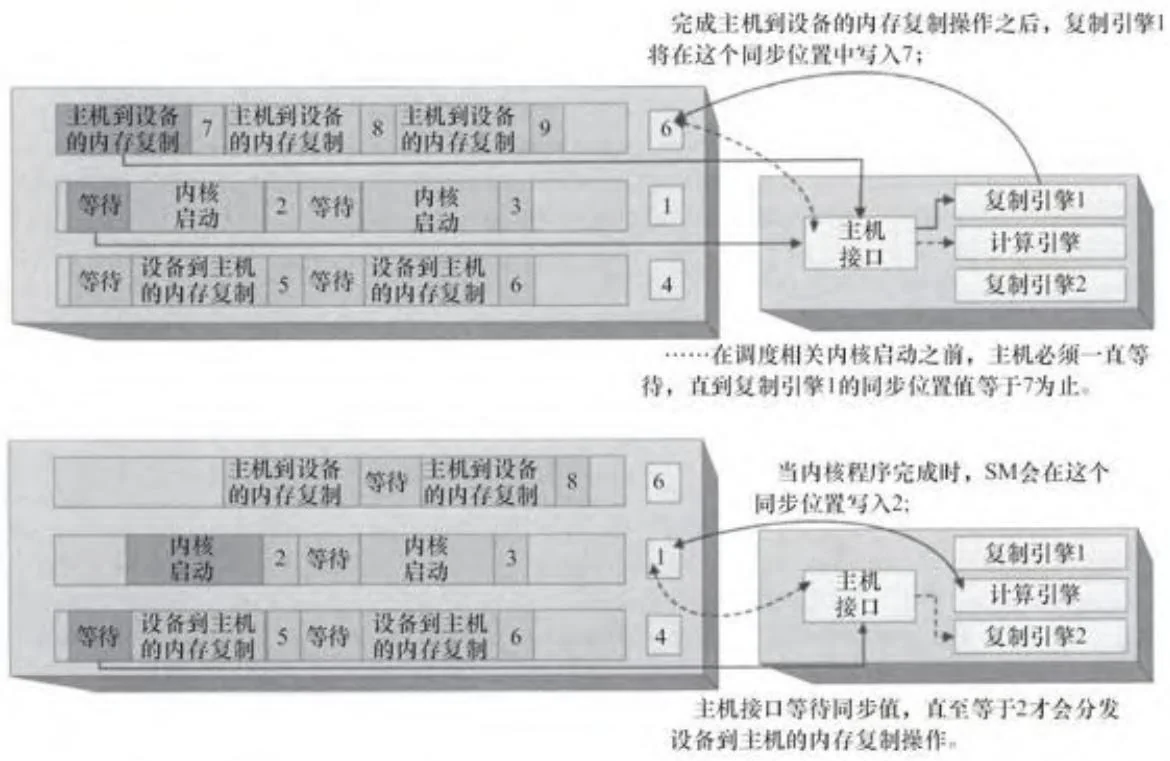
图2-28 内部GPU同步
如图2-28所示,主机接口在协调流同步需求上起着核心作用。例如,在完成所需的内存复制之前,内核是启动不了的。此时,DMA单元可以停止给既定引擎传递命令,直到共享的同步位置获得一个特定值为止。此操作与CPU/GPU同步类似,但GPU是对它内部的不同引擎进行同步的。
在此硬件机制之上的软件抽象模型是一个CUDA流。它在该操作中就像CPU线程一样,每个流都是串行排队,为了并发执行需要多个流。由于引擎间共享命令缓冲区,应用程序必须在不同的流里以软件的方式流水线化它们的请求。因此,它们必须完成
foreach stream
Memcpy device←host
Launch kernel
Memcpy host←device而不是
foreach stream
Memcpy device←host
foreach stream
Launch kernel
foreach stream
Memcpy host←device没有软件方式的流水线,DMA引擎将会通过引擎的同步以维护每个流的串行执行模式,这将打破并发性。
开普勒架构上的多DMA引擎
英伟达最新开普勒架构的硬件实现了一个引擎对应一个DMA单元,从而避免了应用程序需要以软件的方式对它们的流操作进行流水线化。
2.5.4 GPU间同步
由于图2-26~图2-28中的同步位置都是在主机内存上,所以它们可以被系统中的任何一个GPU访问。其结果是,在CUDA 4.0中,英伟达能够在CUDAStreamWaitEvent()和cuStreamWaitEvent()函数的形式中添加GPU之间的同步。这些API调用导致驱动程序为主机接口将等待命令插入当前GPU的命令缓冲区中,使得GPU一直等待,直到事件的给定同步值被写入为止。从CUDA 4.0开始,事件不一定会被等待中的同一个GPU用信号唤醒。流原先只能在单个GPU的硬件单元之间同步执行,现在已提升到可以在GPU之间同步执行了。
[1] 重要提示:在此背景下,GPU的“映射操作”涉及设置指向CPU内存的物理地址的硬件表。该内存也有可能无法被映射到能被CUDA内核程序访问的地址空间中。
[2] http://bit.ly/13UqBm0。