0x13_链表与邻接表
0x13 链表与邻接表
数组是一种支持随机访问,但不支持在任意位置插入或删除元素的数据结构。与之相对应,链表支持在任意位置插入或删除,但只能按顺序依次访问其中的元素。我们可以用一个struct表示链表的节点,其中可以存储任意数据;另外用prev和next两个指针指向前后相邻的两个节点,构成一个常见的双向链表结构。为了避免在左右两端或者空链表中访问越界,我们通常建立额外的两个节点head与tail代表链表头尾,把实际数据节点存储在head与tail之间,来减少链表边界处的判断,降低编程复杂度。
链表的正规形式一般通过动态分配内存、指针等实现,为了避免内存泄露、方便调试,使用数组模拟链表、下标模拟指针也是常见的做法。读者对于链表应该已经有所了解,这里就不再赘述。两种实现形式的参考程序:
struct Node {
int value; // 数据
Node *prev, *next; // 指针
};void initialize() { // 建新链表
head = new Node();
tail = new Node();
head->next = tail;
tail->prev = head;//在p后插入包含数据val的新节点
void insert(Node *p, int val) {
q = new Node();
q->value = val;
p->next->prev = q;
q->next = p->next;
p->next = q; q->prev = p;
}void remove(Node \*p){//删除p p->prev->next $=$ p->next; p->next->prev $=$ p->prev; delete p;
}void recycle() { //链表内存回收
while (head != tail) {
head = head->next;
delete head->prev;
}
delete tail;int initialize(){ tot $= 2$ head $= 1$ tail $= 2$ node[head].next $=$ tail; node[tail].prev $=$ head;
}
int insert(int p, int val){ q $= + +$ tot; node[q].value $=$ val; node[node[p].next].prev $=$ q; node[q].next $\equiv$ node[p].next; node[p].next $=$ q; node[q].prev $=$ p;void remove(int p) {
node[node[p].prev].next = node[p].next;
node[node[p].next].prev = node[p].prev;
}void clear(){//数组模拟链表清空memset(node,0,sizeof(node));head $=$ tail $=$ tot $= 0$ ·【例题】邻值查找
给定一个长度为 的序列 中的数各不相同。对于 中的每一个数 ,求:
以及令上式取到最小值的 (记为 )。若最小值点不唯一,则选择较小的 。
解法一:平衡树(STL set)
把 依次插入一个集合, 则在插入 之前, 集合中保存的就是满足
的所有 。根据题意,我们只需在集合中查找与 最接近的值。
若能维护一个有序集合,则集合中与 最接近的值要么是 的前驱(排在它前一名的值),要么是 的后继(排在它后一名的值),比较前驱、后继与 的差即可。
而二叉平衡树(第0x46节)就是一个支持动态插入、查询前驱以及查询后继的数据结构。在C++中,STL set(第0x71节)也为我们提供了这些功能。
解法二:链表
把序列 从小到大排序,然后依次串成一个链表。注意在排序的同时,建立一个数组 ,其中 表示原始序列中的 处于链表中的哪个位置(一个指针)。
因为链表有序,所以在链表中,指针 指向的节点的 prev 和 next 就分别是 的前驱和后继。通过比较二者与 的差,我们就能求出与 最接近的值。
接下来,我们在链表中删除 指向的节点,该操作是O(1)的。
此时,我们按同样方法考虑 的 prev 和 next,再删除 。
依此类推,最终即可求出与每个 最接近的值。
两种解法的时间复杂度都是 ,其中第二种解法的瓶颈在于排序。
【例题】RunningMedian POJ3784
动态维护中位数问题:依次读入一个整数序列,每当已经读入的整数个数为奇数时,输出已读入的整数构成的序列的中位数。
在 节中,我们讨论了本题的“对顶堆”做法。这里我们再介绍一种使用链表的离线做法。我们可以先把整个序列读入进来,排序之后依次插入一个链表,此时我们可以知道整个序列的中位数 。随后,我们倒序考虑本题中的读入过程,也就是把整数从链表中一个个删去。
与上一道题一样,为了删除一个整数,我们需要找到该整数在链表中对应的节点。上一题建立了一个指针数组,但是本题的整数范围较大,需要用Hash表(第0x14节)或者STLmap(第0x71节)记录这些指针。
每次删去一个整数 后,要么中位数不变,要么新的中位数与原来中位数 的位置相邻,通过 和 的大小关系以及链表中元素的总个数分情况讨论,很容易确定新的中位数 。
在上面两道例题中,我们都用了“倒序处理”的方法,利用链表容易执行“删除”操作的特性,快速地找到了答案。
邻接表
在与链表相关的诸多结构中,邻接表是相当重要的一个。它是树与图结构的一般化
存储方式,还能用于实现我们在下一节中即将介绍的开散列 Hash 表。实际上,邻接表可以看成“带有索引数组的多个数据链表”构成的结构集合。在这样的结构中存储的数据被分成若干类,每一类的数据构成一个链表。每一类还有一个代表元素,称为该类对应链表的“表头”。所有“表头”构成一个表头数组,作为一个可以随机访问的索引,从而可以通过表头数组定位到某一类数据对应的链表。为了方便起见,本书将这类结构统称为“邻接表”结构。
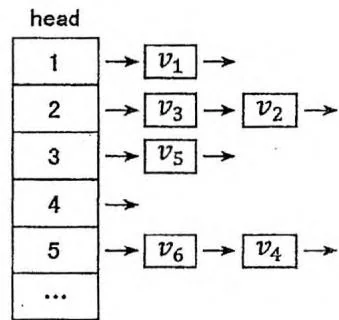
如下图左侧所示,这是一个存储了6个数据节点 的邻接表结构。这6个数据节点被分成4类,通过表头数组head可以定位到每一类所构成的链表进行遍历访问。
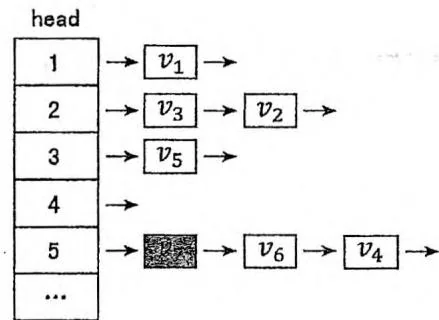
当需要插入新的数据节点时,我们可以通过表头数组 head 定位到新的数据节点所属类别的链表表头,将新数据在表头位置插入。如下图右侧所示,在邻接表中插入了属于第 5 类的新数据节点 。
在一个具有 个点 条边的有向图结构中,我们可以把每条边所属的“类别”定义为该边的起点标号。这样所有边被分成 类,其中第 类就由“从 出发的所有边”构成。通过表头 head ,我们很容易定位到第 类对应的链表,从而访问从点 出发的所有边。
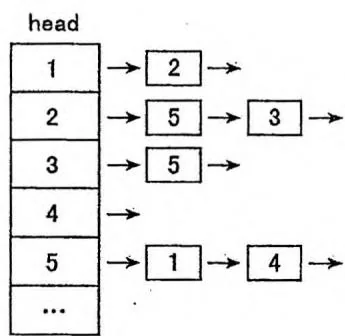
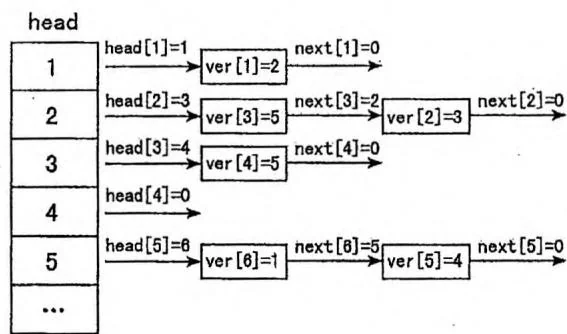
上图是在邻接表中插入一张5个点、6条边的有向图之后的状态。这6条边按照
插入的顺序依次是 。上页图左侧展示了这个邻接表存储的宏观信息,上页图右侧展示了采用“数组模拟链表”的实现方式时,内部数据的实际存储方式。head与next数组中保存的是“ver①数组的下标”,相当于指针,其中0表示指向空。ver数组存储的是每条边的终点,是真实的图数据。
// 加入有向边(x,y),权值为z
void add(int x, int y, int z) {
ver[++tot] = y, edge[tot] = z; // 真实数据
next[tot] = head[x], head[x] = tot; // 在表头x处插入
}// 访问从 $\mathbf{x}$ 出发的所有边
for (int i = head[x]; i; i = next[i]) {
int y = ver[i], z = edge[i];
// 找到了一条有向边(x, y),权值为z
}上面的代码片段用数组模拟链表的方式存储了一张带权有向图的邻接表结构。
对于无向图,我们把每条无向边看作两条有向边插入即可。有一个小技巧是,结合在第 节提到的“成对变换”的位运算性质,我们可以在程序最开始时,初始化变量 。这样每条无向边看成的两条有向边会成对存储在 ver 和 edge 数组的下标“2和3”“4和5”“6和7”……的位置上。通过对下标进行 的运算,就可以直接定位到与当前边反向的边。换句话说,如果 是第 条边的终点,那么 就是第 条边的起点。