13.5_线程束扫描
13.5 线程束扫描
到目前为止,我们集中精力于构建自上而下的扫描。在所有3个扫描实现的底层,隐含着完全不同的软件方法。对于大小为32或更小的子数组,我们使用一个基于Kogge-Stone电路的特殊线程束扫描(见图13-11)。Kogge-Stone电路效率低下,这意味着它们尽管深度不大也要花费许多运算。但是就线程束水平来说(CUDA硬件的执行资源是可用的,不管开发者是否使用它们),Kogge-Stone电路在CUDA硬件上工作良好。
代码清单13-13给出了一个使用__device__限定符的程序,这个程序设计在共享内存上运行,对线程来说,这是相互交换数据最快的方式。因为这里不存在共享内存的存储片冲突,并且这个程序运行在线程束粒度,在向共享内存更新数据的过程中无须线程同步。
代码清单13-13 scanWarp
template<class T> inline_device_T scanWarp( volatile T *sPartials) {
const int tid = threadIdx.x;
const int lane = tid & 31;
if (lane >= 1) sPartials[0] += sPartials[-1];
if (lane >= 2) sPartials[0] += sPartials[-2];
if (lane >= 4) sPartials[0] += sPartials[-4];
if (lane >= 8) sPartials[0] += sPartials[-8];
if (lane >= 16) sPartials[0] += sPartials[-16];
return sPartials[0];
}13.5.1 零填充
我们可以减少实现线程束扫描必须的机器指令数:通过在线程束数组里交错放置16个0元素,免除条件判断语句。代码清单13-14给出了scanWarp的一个版本,这里假定在共享内存的基址前有16个零元素。
代码清单13-14 scanWarp0
template<class T> device_T scanWarp0( volatile T *sharedPartials, int idx) {
const int tid = threadIdx.x;
const int lane = tid & 31;
sharedPartials[idx] += sharedPartials[idx - 1];
sharedPartials[idx] += sharedPartials[idx - 2];
sharedPartials[idx] += sharedPartials[idx - 4];
sharedPartials[idx] += sharedPartials[idx - 8];
sharedPartials[idx] += sharedPartials[idx - 16];
return sharedPartials[idx];
}图13-15显示了交错方案如何在256个线程(包含8个线程束)组成的线程块中运行。共享内存的索引按如下方法计算。
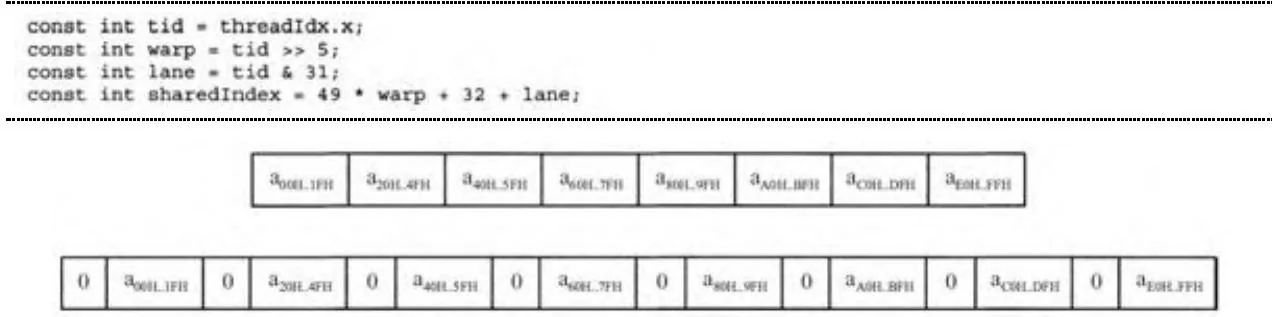
图13-15 线程束扫描的交错零值
partials[sharedIndex-16] = 0;
在块扫描子程序里,这种变化会影响共享内存的寻址。每个线程束的部分和的索引必须加上偏移16,来启用单线程束的扫描操作,该操作计算基本和。最后,内核启动必须预留足够的共享内存来保存部分和以及零值。
13.5.2 带模板的版本
扫描算法的更快的零填充实现需要更多的共享内存,这一资源需求不是所有应用都能满足的。为了确保我们的代码能在两个场合中运行,代码清单13-15显示了一个以bool型变量bZeroPad为参数的辅助函数。该scanSharedMemory函数返回一个给定大小线程块所需要的共享内存量。scanSharedIndex函数返回一个给定线程相应的共享内存索引。后面的代码清单13-16给出了scanWarp带模板的版本,可同时工作于零填充和非零填充两种场合。
代码清单13-15 用于零填充方式的共享内存辅助函数
代码清单13-16 scanWarp(带模板版本)
template <bool bZeroPad>
inline _device__int
scanSharedIndex( int tid )
{
if ( bZeroPad ) {
const int warp = tid >> 5;
const int lane = tid & 31;
return 49 * warp + 16 + lane;
}
else {
return tid;
}template<class T, bool bZeroPadded> inline_device_T scanWarp( volatile T *sPartials) {
T t = sPartials[0];
if (bZeroPadded) {
t += sPartials[-1]; sPartials[0] = t;
t += sPartials[-2]; sPartials[0] = t;
t += sPartials[-4]; sPartials[0] = t;
t += sPartials[-8]; sPartials[0] = t;
t += sPartials[-16]; sPartials[0] = t;
}
else {
const int tid = threadIdx.x;
const int lane = tid & 31;
if (lane >= 1) { t += sPartials[-1]; sPartials[0] = t; }
if (lane >= 2) { t += sPartials[-2]; sPartials[0] = t;}
if (lane >= 4) { t += sPartials[-4]; sPartials[0] = t;}
if (lane >= 8) { t += sPartials[-8]; sPartials[0] = t;}
if (lane >= 16) { t += sPartials[-16]; sPartials[0] = t;}
} return t;13.5.3 线程束洗牌
SM 3.0指令集添加了线程束洗牌指令,该指令使寄存器能在32个线程组成的线程束中进行交换。线程束洗牌的“向上”和“向下”变形能够分别用于执行扫描和反向扫描。洗牌指令带两个参数,一个是用于交换的寄存器,另一个是应用于线程编号的偏移量。它返回一个断定结果,当线程是非活动的或者线程的偏移量超出了线程束范围时,断定的对应位为“假”。
代码清单13-17给出了scanWarpShuffle函数,它是使用洗牌指令实现包容性线程束扫描的设备函数。它的模板参数是整型,通常传入的值为5,因为5正好是线程束大小32的以2为底的对数。鉴于编译器无法生成有效处理洗牌指令返回的断定结果的代码,scanWarpShuffle使用一个内联实现在PTX中的辅助函数scanWarpShuffle_step。
代码清单13-17 scanWarpShuffle设备函数
device__forceinline
int
scanWarpShuffle_step(int partial, int offset)
{
int result;
asm{
".reg .u32 r0;"
".reg .pred p;"
"shfl.up.b32 r0|p, %1, %2, 0;"
"@p add.u32 r0, r0, %3;"
"mov.u32 %0, r0;}
: "=r"(result) : "r"(partial), "r"(offset), "r"(partial));
return result;
}
template <int levels>
device__forceinline
int
scanWarpShuffle(int mysum)
{
for (int i = 0; i < levels; ++i)
mysum = scanWarpShuffle_step(mysum, 1 << i);
return mysum;
}代码清单13-18显示了如何扩展scanWarpShuffle函数,利用共享内存扫描在一个线程块的值。采用与代码清单13-13一样的线程块扫描形式,scanBlockShuffle函数使用线程束洗牌扫描每个线程束。每个线程束把它自己的部分和写到共享内存中,然后再一次使用线程束洗牌,这次仅使用单个的线程束,来扫描这些基本和。最后,每个线程束加上对应的基本和来计算最终输出值。
代码清单13-18 scanBlockShuffle设备函数
template <int logBlockSize>
device_
int
scanBlockShuffle(int val, const unsigned int idx)
{
const unsigned int lane = idx & 31;
const unsigned int warpid = idx >> 5;
_shared__int sPartials[32];
// Intra-warp scan in each warp
val = scanWarpShuffle<5>(val);
// Collect per-warp results
if (lane == 31) sPartials[warpid] = val;
_syncthreads();
// Use first warp to scan per-warp results
if (warpid == 0) {
int t = sPartials[lane];
t = scanWarpShuffle<logBlockSize-5>(t);
sPartials[lane] = t;
}
_syncthreads();
// Add scanned base sum for final result
if (warpid > 0) {
val += sPartials[warpid - 1];
}
return val;
}13.5.4 指令数对比
为了评价本节所讨论的不同线程束扫描算法,我们针对SM 3.0进行编译,并且使用cuojdump来反汇编3个实现。得到的结果如下:
·代码清单13-19给出的非零填充实现共有30条指令,并包括了大量的分支(配对使用的SSY的/.S指令执行分支栈的压入和弹出,如本书第8.4.2小节所述)。
·代码清单13-20给出的零填充的实现共有17条指令,它在读取共享内存之前不需要检查线程编号。需要注意的是,一旦共享内存上的操作都限定在一个线程束内,就无须通过调用__syncthreads()内置函数进行栅栏同步,该同步在SASS里编译成BAR.SYNC指令。
·代码清单13-21中给出的洗牌实现只有11条指令。
在人工合成的负载上测试(分离出线程束扫描),可以证实,基于洗牌的实现显著快(约2倍)于代码清单13-19中给出的一般情况。
代码清单13-19 线程束扫描的SASS代码(无零填充)
/\*0070\*/ SSY 0xa0;
/\*0078\*/ @PO NOP.S CC.T;
/\*0088\*/ LDS R5, [R3+-0x4];
/\*0090\*/ IADD R0, R5, R0;
/\*0098\*/ STS.S [R3], R0;
/\*00a0\*/ ISETP.LT.U32.AND P0, pt, R4, 0x2, pt;
/\*00a8\*/ SSY 0xd8;
/\*00b0\*/ @PO NOP.S CC.T;
/\*00b8\*/ LDS R5, [R3+-0x8];
/\*00c8\*/ IADD R0, R5, R0;
/\*00d0\*/ STS.S [R3], R0;
/\*00d8\*/ ISETP.LT.U32.AND P0, pt, R4, 0x4, pt;
/\*00e0\*/ SSY 0x110;
/\*00e8\*/ @PO NOP.S CC.T;
/\*00f0\*/ LDS R5, [R3+-0x10];
/\*00f8\*/ IADD R0, R5, R0;
/\*0108\*/ STS.S [R3], R0;
/\*0110\*/ ISETP.LT.U32.AND P0, pt, R4, 0x8, pt;
/\*0118\*/ SSY 0x140;
/\*0120\*/ @PO NOP.S CC.T;
/\*0128\*/ LDS R5, [R3+-0x20];
/\*0130\*/ IADD R0, R5, R0;
/\*0138\*/ STS.S [R3], R0;
/\*0148\*/ ISETP.LT.U32.AND P0, pt, R4, 0x10, pt;
/\*0150\*/ SSY 0x178;
/\*0158\*/ @PO NOP.S CC.T;
/\*0160\*/ LDS R4, [R3+-0x40];
/\*0168\*/ IADD R0, R4, R0;
/\*0170\*/ STS.S [R3], R0;
/\*0178\*/ BAR.SYNC 0xO;代码清单13-20 线程束扫描的SASS代码(零填充)
/\*0058\*/ LDS R4, [R3+-0x4];
/\*0060\*/ LDS R0, [R3];
/\*0068\*/ IADD R4, R4, R0;
/\*0070\*/ STS [R3], R4;
/\*0078\*/ LDS R0, [R3+-0x8];
/\*0088\*/ IADD R4, R4, R0;
/\*0090\*/ STS [R3], R4;
/\*0098\*/ LDS R0, [R3+-0x10];
/\*00a0\*/ IADD R4, R4, R0;
/\*00a8\*/ STS [R3], R4;
/\*00b0\*/ LDS R0, [R3+-0x20];
/\*00b8\*/ IADD R4, R4, R0;
/\*00c8\*/ STS [R3], R4;
/\*00d0\*/ LDS R0, [R3+-0x40];
/\*00d8\*/ IADD R0, R4, R0;
/\*00e0\*/ STS [R3], R0;
/\*00e8\*/ BAR.SYNC 0x0;代码清单13-21 线程束扫描的SASS代码(基于洗牌)
/\*0050\*/ SHFL.up P0,R4,R0,0x1,0x0; /\*0058\*/ IADD.X R3,R3,c[0x0][0x144]; /\*0060\*/ @PO IADD R4,R4,R0; /\*0068\*/ SHFL.up P0,R0,R4,0x2,0x0;/*0070*/ @PO IADD R0, R0, R4;
/*0078*/ SHFL.UP P0, R4, R0, 0x4, 0x0;
/*0088*/ @PO IADD R4, R4, R0;
/*0090*/ SHFL.UP P0, R0, R4, 0x8, 0x0;
/*0098*/ @PO IADD R0, R0, R4;
/*00a0*/ SHFL.UP P0, R4, R0, 0x10, 0x0;
/*00a8*/ @PO IADD R4, R4, R0;