10.6_GPU的工作调度机制
10.6 GPU的工作调度机制
虽然从逻辑上来看,不同的流之间是相互独立的,但事实上这种理解并不完全符合GPU的队列机制。程序员可以将流视为有序的操作序列,其中既包含内存复制操作,又包含核函数调用。然而,在硬件中并没有流的概念,而是包含一个或多个引擎来执行内存复制操作,以及一个引擎来执行和函数。这些引擎彼此独立地对操作进行排队,因此将导致如图10.2所示的任务调度情形。图中的箭头说明了硬件引擎如何调度流中队列的操作并实际执行。
因此,在某种程度上,用户与硬件关于GPU工作的排队方式有着完全不同的理解,而CUDA驱动程序则负责对用户和硬件进行协调。首先,在操作被添加到流的顺序中包含了重要的依赖性。例如,在图10.2中,第0个流对A的内存复制需要在对B的内存复制之前完成,而对B的复制又要在核函数A启动之前完成。然而,一旦这些操作放入到硬件的内存复制引擎和核函数执行引擎的队列中时,这些依赖性将丢失,因此CUDA驱动程序需要确保硬件的执行单元不破坏流内部的依赖性。
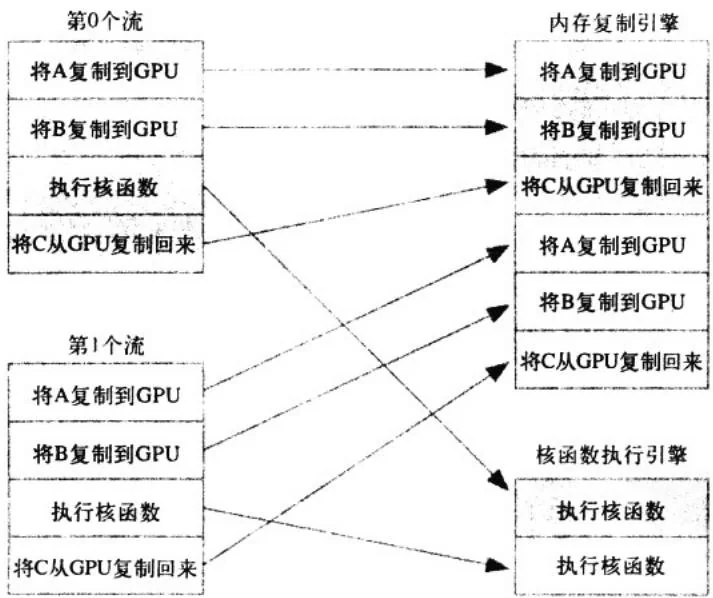
图10.2 将CUDA流映射到GPU引擎
这意味着什么?我们来看看10.4节中实际发生的情况。如果重新观察代码,将看到应用程序基本上是对a调用一次cudaMemcpyAsync(),对b调用一次cudaMemcpyAsync(),然后再是执行核函数以及调用cudaMemcpyAsync()将c复制回主机。应用程序首先将第0个流的所有操作放
入队列,然后是第1个流的所有操作。CUDA驱动程序负责按照这些操作的顺序把它们调度到硬件上执行,这就维持了流内部的依赖性。在图10.3中说明了这些依赖性,其中从复制操作到核函数的箭头表示,复制操作要等核函数执行完成之后才能开始。
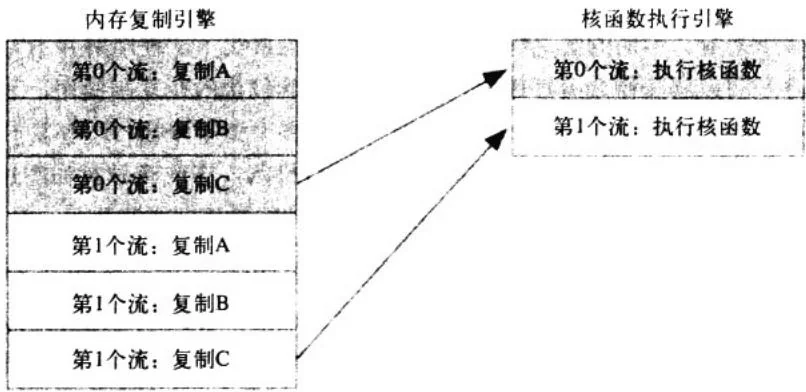
图10.3 箭头表示cudaMemcpyAsync()对核函数的依赖性
假定理解了GPU的工作调度原理后,我们可以得到关于这些操作在硬件上执行的时间线,如图10.4所示。
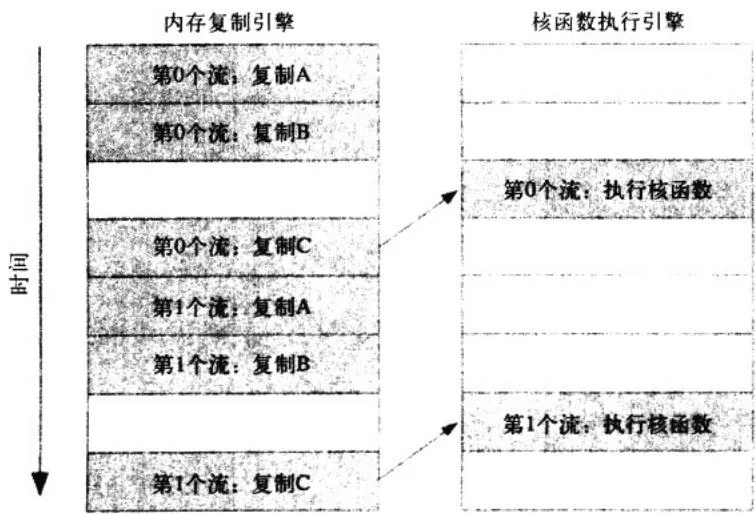
图10.4在“使用多个CUDA流”中示例程序的执行时间线
由于第0个流中将c复制回主机的操作要等待核函数执行完成,因此第1个流中将a和b复制到GPU的操作虽然是完全独立的,但却被阻塞了,这是因为GPU引擎是按照指定的顺序来执行工作。这种情况很好地说明了为什么在程序中使用了两个流却无法获得加速的窘境。这个问题的直接原因是我们没有意识到硬件的工作方式与CUDA流编程模型的方式是不同的。
这里需要说明的情况是,当要确保相互独立的流能够真正地并行执行时,我们自己要起到一定的作用。记住,硬件在处理内存复制和核函数执行时分别采用了不同的引擎,因此我们需要知道,将操作放入流中队列中的顺序将影响着CUDA驱动程序调度这些操作以及执行的方式。在10.7节中,我们将看到如何帮助硬件实现内存复制操作与核函数执行的重叠。