10.7_高效地使用多个CUDA流
10.7 高效地使用多个CUDA流
正如在10.6节中看到的,如果同时调度某个流的所有操作,那么很容易在无意中阻塞另一个流的复制操作或者核函数执行。要解决这个问题,在将操作放入流的队列时应采用宽度优先方式,而非深度优先方式。也就是说,不是首先添加第0个流的所有四个操作(即a的复制、b的复制、核函数以及c的复制),然后不再添加第1个流的所有四个操作,而是将这两个流之间的操作交叉添加。首先,将a的复制操作添加到第0个流,然后将a的复制操作添加到第1个流。接着,将b的复制操作添加到第0个流,再将b的复制操作添加到第1个流。接下来,将核函数调用添加到第0个流,再将相同的操作添加到第1个流中。最后,将c的复制操作添加到第0个流中,然后将相同的操作添加到第1个流中。
要更具体地理解这个操作,我们来看实际的代码。我们修改了这些操作被分配到两个流的顺序,这基本上只需要对代码进行复制/粘贴。应用程序中的其他代码保持不变,这意味着我们的修改只局限于for()循环。采用宽度优先方式将操作分配到两个流的代码如下所示:
for (int i=0; i<FULL_DATA_SIZE; i+=N*2) { //将复制a的操作放入stream0和stream1的队列
HANDLE_ERROR(udaMemcpyAsync( dev_a0, host_a+i, N * sizeof(int),udaMemcpyHostToDevice, stream0));
HANDLE_ERROR(udaMemcpyAsync( dev_al, host_a+i+N, N * sizeof(int),udaMemcpyHostToDevice, stream1));
//将复制b的操作放入stream0和stream1的队列
HANDLE_ERROR(udaMemcpyAsync( dev_b0, host_b+i, N * sizeof(int),udaMemcpyHostToDevice, stream0));
HANDLE_ERROR(udaMemcpyAsync( dev_bl, host_b+i+N, N * sizeof(int),udaMemcpyHostToDevice, stream1));//将核函数的执行放入stream1和stream1的队列中
kernel<<N/256,256,0, stream0>>>(dev_a0,dev_b0,dev_c0);
kernel<<N/256,256,0, stream1>>>(dev_al,dev_b1,dev_c1);
//将复制c的操作放入stream0和stream1的队列
HANDLE_ERROR(cudaMemcpyAsync(host_c+i,dev_c0,N * sizeof(int),cudaMemcpyDeviceToHost,streamO));
HANDLE_ERROR(cudaMemcpyAsync(host_c+i+N,dev_cl,N * sizeof(int),cudaMemcpyDeviceToHost,streaml));如果内存复制操作的时间与核函数执行的时间大致相当,那么新的执行时间线将如图10.5所示。引擎间的依赖性通过箭头高亮显示,可以看到在新的调度顺序中,这些依赖性仍然能得到满足。
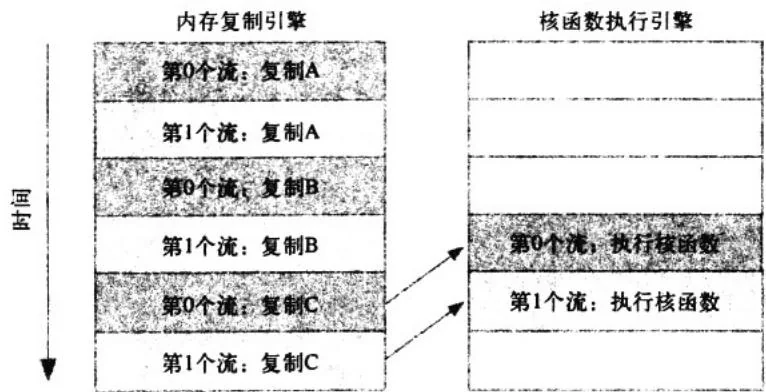
图10.5 改进后示例的执行时间线,其中箭头表示引擎间的依赖性
由于采用了宽度优先方式将操作放入各个流的队列中,因此第0个流对c的复制操作将不会阻塞第1个流对a和b的内存复制操作。这使得GPU能够并行地执行复制操作和核函数,从而使应用程序的运行速度显著加快。新代码的运行时间为48ms,比最初使用两个流的应用程序快了 。如果应用程序的所有计算和内存复制操作都能重叠,那么可以在性能上获得近两倍的提升,因为执行复制操作的引擎和执行核函数的引擎将始终保持在运行。