评价点估计好不好有三个指标:无偏性是指估计量的期望和总体期望一样。 有效性是指估计量的方差应尽可能小,相合性是指当取样数量无限大时,估计量和真实值应无限接近
点估计好坏的评价标准
对于参数估计,采用不同的评估方法会有不同的结论,比如要估算一个学校里男生的平均身高,可以随机抽查100名学生,计算样本的平均值、中位数、众数、最大值和最小值的平均数、截尾均值等作为总体的平均值,我们希望得到的估计量能体现总体的真实参数,那么在同一参数的多个估计量当中,哪一个是最好的估计量呢?自然需要给出评价估计量优劣的标准,这就是本节介绍的无偏性、有效性和相合性。
注: 截尾均值是指由于均数较易受极端值的影响,因此可以考虑将数据进行行排序后,按照一定比例去掉最两端的数据,只使用中部的数据来求均数这叫做截尾均值
无偏性
题目释义,偏,偏差的意思。 无偏性,就是没有偏差。无偏性就是要求 样本的期望值 等于 总体的期望值。
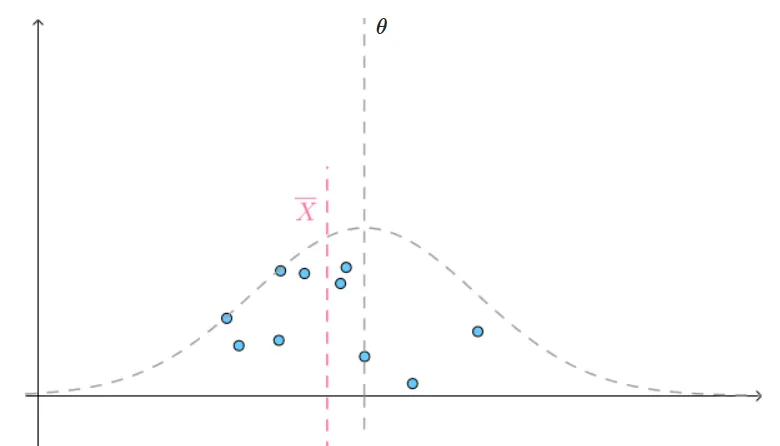
考虑下面一种情况:为了估算全校男生的平均身高,我们可以对其随机采样,比如我们采样10次,每次采样10人,这样就得到10组数据,
data1:170,168,182,173,174,175,154,172,160,179
算出平均值 X1ˉ=10170+168+182+173+174+175+154+172+160+179=170.7
data2:161,165,172,173,174,178,179,180,177,179
算出平均值 X2ˉ=10161+165+172+173+174+178+179+180+177+179=173.8
data3:181,165,172,173,176,173,175,163,162,176
算出平均值 X3ˉ=10181+165+172+173+176+173+175+163+162+176=171.6
... 算出10组平均值,得到10组样本均值。(注意:对于每次采样获得的值叫做观测值,一般用x表示,而算出来的平均值是样本均值,一般用X表示)
如果设全校男生平均身高的真实值为θ,可以发现每次取样的均值Xˉ都在θ值附近跳动,也许我们永远不知道全校男生的真实值是多少,但是我们可以给出置信区间,比如 95%把握保证男生的平均身高为 172cm,详见 置信区间
 {width=500px}
{width=500px}
在上面采样里,如果用θ^ 表示估算的身高,可以看到 θ^ 是Xˉ的函数,因此,给出如下定义:
定义
估计量 θ^(X1,X2,⋯,Xn) 是一个随机变量,对于一次具体的观测结果来说,θ^的取值与真实的参数值 θ 一般会有偏差,我们希望 θ^ 的取值能在 θ 附近波动,而且在多次观测中,θ^ 的平均值 E(θ^) 应与 θ 吻合,由此引出了无偏性的概念.
设 θ^=θ^(X1,X2,⋯,Xn) 是未知参数 θ 的估计量,若E(θ^)=θ 则称 θ^ 为 θ 的无偏估计量. 如果 limθ^)=θ 称为渐进无偏估计。
在实际应用中,要求估计量具有无偏性是有实际意义的.例如,在大批商品的交易中,买卖双方一般通过抽样去估计产品的次品率.若估计值高于实际值,将给卖家带来损失.反之,若估计值低于实际值,就会给买家带来损失.但只要采用的估计量是无偏估计量,而且双方的买卖是长期的,则总的来说是互不吃亏的.
无偏性解释
估计量的无偏性有两个含义. 第一个含义是没有系统性的偏差,不论你用什么样的估计量 θ^ 去估计 θ ,总是时而偏低, 时而偏高. 无偏性表示, 把这些正负偏差在概率上平均起来,其值为 0 。比如您买了一瓶饮料,虽然包装上标准为500ml,但是由于机器问题导致有时候保证超过500ml一点,有时候低于500ml一点,只要再合理范围,我们认为这都是合格的,因此, 无偏估计不等于在任何时候都给出正确无误的估计.
例设 (X1,X2,⋯,Xn) 是来自总体 X 的一个样本,总体 X∼U(0,θ) 其中 θ>0 未知,
试求
(1)θ 的矩估计量 θ^1 ;
(2)θ 的极大似然估计量 θ^2 ;
(3) 问 θ^1,θ^2 是不是未知参数的无偏估计? 若不是,将其修正为无偏估计。
解 (1)由矩估计定义可知
由于 E(X)=2θ ,则 θ=2E(X) ,故 θ 的矩估计量 θ^1=2Xˉ.
(2) 似然函数 L(θ)={θn1,0,0⩽x1,⋯,xn⩽θ 其他 .
因 L(θ) 不可导,可按最大似然法的基本思想确定 θ^ 。欲使 L(θ) 最大,θ 应尽量小但又不能太小,它必须同时满足 θ⩾xi(i=1,⋯,n) ,即 θ⩾max(x1,⋯,xn) ,否则 L(θ)=0 ,而 0 不可能是 L(θ) 的最大值。因此,当 θ=max{x1,⋯,xn} 时,L(θ) 可达最大。所以 θ 的最大似然估计为 θ^=max{X1,⋯,Xn} .
此例说明,当似然函数L(θ)关于θ单调递增(或递减)时,其极值点为θ的最大(或最小)取值点
现在我们分析一下上面两个估计的通俗意义,假设抽查一批钢板厚度服从均匀分布(0,θ),抽查的结果是:2.1cm2.4cm2.2cm2.1cm2.3cm 其平均值为
Xˉ=(2.1+2.4+2.2+2.1+2.3)/5=2.2cm ,当使用矩估计时,θ=2Xˉ=2.2∗2=4.4 , 而当使用极大似然估计时,θ 为样本里最大值,即θ=2.4 ,因此一个认为均匀分布是(0,4.4) , 一个认为均匀分布是(0,2.4)
(3)
①E(θ^1)=E(2Xˉ)=2E(X)=2×2θ=θ ;
②由次序统计量的分布知当 y∈(0,θ) 时, X(n) 的概率密度
函数为
fn(y)=n(θy)n−1⋅θ1=θnnyn−1 故 E(θ^2)=E(X(n))=∫0θy⋅θnnyn−1dy=n+1nθ
因此,矩估计是无偏估计而极大似然估计不是无偏估计。
但是注意到 limn→+∞E(θ^2)=θ ,因此 X(n) 是 θ 的渐近无偏估计。
定义: θ^2∗=nn+1θ^2=nn+1X(n)
则满足 E(θ^2∗)=θ ,即修正后的 nn+1X(n) 是 θ 的无偏估计。
方差
例 已知 B2=n1∑i=1n(Xi−Xˉ)2 和 S2=n−11∑i=1n(Xi−Xˉ)2 都是总体方差 σ2 的估计量,问:哪个估计量更好?
解 由于
E(S2)=D(X)=σ2 故样本方差 S2=n−11∑i=1n(Xi−Xˉ)2 是 σ2 的无偏估计量.而
E(B2)=E(nn−1S2)=nn−1σ2=σ2 所以 B2=n1∑i=1n(Xi−Xˉ)2 不是 σ2 的无偏估计量.
这也正是在实际应用中样本方差采用 S2=n−11∑i=1n(Xi−Xˉ)2 而不用 B2=n1∑i=1n(Xi−Xˉ)2 的原因。
上述两例的结论与总体的分布类型没有关系。只要总体均值存在,样本均值总是它的无偏估计量;只要总体方差存在,样本方差总是它的无偏估计量.
本题解释:在样本的均值与方差 里,给出了方差要除以n−1 而不是除以n, 就是为了拟合 无偏性,最主要的是自由度少了1
例设总体 X∼N(μ,σ2),(X1,X2,⋯,Xn) 为来自该总体的一个样本,
已求得:当 μ 已知时, σ2 的矩估计量 σ^12=n1∑i=1nXi2−μ2 ;
当 μ末知时,σ2 的矩估计量 σ^22=n1∑i=1nXi2−(Xˉ)2=n1∑i=1n(Xi−Xˉ)2=Sn2.
分别讨论是 σ^12、σ^22 的无偏性.
解
E(σ^12)=n1i=1∑nE(Xi−μ)2=n1i=1∑nE(X−μ)2=E(X−μ)2=E(X−E(X))2=D(X)=σ2 故 σ^12 是 σ2 的无偏估计.
E(σ^22)=E(Sn2)=nn−1σ2=σ2,n>2 故 σ^22=Sn2 不是 σ2 的无偏估计.
将 Sn2 修正为 S2 ,满足 E(S2)=σ2 ,则 S2 是 σ2 的无偏估计量.
上面粒子可以这么理解:假设测量5组学生每组10人,然后得到5组的平均值 172,173,172,175,174,再用这5组均值估算全校学生的身高,现在告诉你①全校学生的真实身高是173,那我们就要估算方差是多少。②全校学生的真实身高未知,我们估算方差又是多少。对于后面这个情况因为实际均值未知,我们就用样本均值替代总体均值。
方差无偏性定理
若总体 X 的均值 E(X)=μ ,方差 D(X)=σ2 ,样本为 (X1,X2,⋯,Xn) , 则有
(1) E(Xˉ)=μ,
(2) E(S2)=σ2,E(Sn2)=nn−1σ2,n≥2
因此,样本均值是总体均值的无偏估计,样本方差是总体方差的无偏估计,而样本的二 阶中心矩是总体方差的渐䜣无偏估计。
上面定理说明了在样本方差 S2=n−11∑i=1n(Xi−Xˉ)2 中 n−11 的作用.对于样本的二阶中心矩 n1∑i=1n(Xi−Xˉ)2=nn−1S2 ,由于其数学期望为 nn−1σ2=σ2 ,所以 n1∑i=1n(Xi−Xˉ)2 是 σ2 的有偏估计.
但由于 limn→∞E[n1∑i=1n(Xi−Xˉ)2]=σ2 ,因此 n1∑i=1n(Xi−Xˉ)2 是 σ2 的渐近无偏估计.为了便于与 S2 对比,也将样本的二阶中心矩 n1∑i=1n(Xi−Xˉ)2 记为 Sn2 ,即 Sn2=n1∑i=1n(Xi−Xˉ)2 。
例 设总体 X∼P(λ) ,对任意的常数 c∈(0,1) ,问 cXˉ+(1−c)S2是否为 λ 的无偏估计?
解 由于 X∼P(λ) ,故 EX=DX=λ ,由定理知道, Xˉ 和 S2 均为 λ 的无偏估计.又因为 c+(1−c)=1 , cXˉ+(1−c)S2 为 λ 的无偏估计.
例题
例 设总体 X∼B(1,p),(X1,X2,⋯,Xn) 为来自总体 X 的样本,试问 p^=Xˉ 是否为未知参数 p 的无偏估计?
解 由于 Ep^=EXˉ=EX=p ,所以 p^=Xˉ 是 p 的无偏估计.
例 设总体 X 的概率密度为
f(x)={3θ22x,0,θ<x<2θ, 其他, 其中 θ 是未知参数.X1,X2,⋯,Xn 为来自总体 X 的简单样本,选择适当的常数 c ,使 c∑i=1nXi2 是 θ2 的无偏估计量.
(解)由于 c∑i=1nXi2 是 θ2 的无偏估计量,所以
E(ci=1∑nXi2)=θ2 而
E(ci=1∑nXi2)E(X2)=ci=1∑nE(Xi2)=ci=1∑nE(X2)=∫θ2θx23θ22xdx=25θ2 所以
E(ci=1∑nXi2)=25cnθ2=θ2 故
c=5n2